

دوره 23، شماره 88 - ( 2-1402 )
جلد 23 شماره 88 صفحات 83-9 |
برگشت به فهرست نسخه ها



![]()
![]()
![]()
Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
oreyzi H. (2023). Humpty Dumpty domination on correlational data analysis in social welfare researches. Social Welfare Quarterly. 23(88), 9-83. doi:10.32598/refahj.23.88.1908.5
URL: http://refahj.uswr.ac.ir/article-1-3991-fa.html
URL: http://refahj.uswr.ac.ir/article-1-3991-fa.html
عریضی حمیدرضا.(1402). زبان خصوصی در تحلیل دادههای رابطهای در پژوهشهای رفاه اجتماعی رفاه اجتماعی 23 (88) :83-9 10.32598/refahj.23.88.1908.5

واژههای کلیدی: زبان خصوصی، خطای آماری، کاربرد نابجای زبان، زبان نادرست در فرضیه آزمایی، رفاه اجتماعی
متن کامل [PDF 989 kb]
(2404 دریافت)
| چکیده (HTML) (3404 مشاهده)
متأسفانه در پژوهشهای رابطهای کمتر از رگرسیون لوجستیک استفاده میشود؛ درصورتیکه توانمندیهای آن بسیار است.
مثال مشهور آن را میتوان در پژوهش زیسمن و گانزاخ (2021) دید که در پژوهش خود نشان دادهاند که هوش در موفقیت تحصیلی دارای نسبت شانس 48 تا 90 برابر اراده و عزم است و هوش در شغل دارای نسبت شانس 13 نسبت به اراده و عزم است. درواقع آنجلاداک ورث توانسته بود در یک برنامه مشهور TED نشان دهد که عزم و اراده در پیشرفت تحصیلی بسیار مهمتر از هوش است. در اینجا دادهها به کمک آمدهاند و نشان دادهاند که این ادعا نادرست است. سخنرانی در 2013 ایراد شده بود و تا تابستان 2020، بیستویک میلیون نفر آن را مشاهده کرده بودند. ایدهای عمیقاً در جامعه رواج یافته بود اما یک پژوهش رگرسیون نشان داد که این ایده واقعیت ندارد.
همه پژوهشهای بررسی شده در این مقاله بهنوعی یا با درک نادرستی از تحلیل عاملی، تحلیل مسیر و تحلیل مدل معادلات ساختاری (SEM) و یا عدم تمایز بین تحلیلهای اکتشافی و تأییدی و یا با درک نادرست رگرسیون ازجمله تفاوت قائل نشدن بین رگرسیون چندگانه و رگرسیون چند متغیره روبرو بودند. به همین دلیل خطوط راهنما هم برای نویسندگان و هم برای داوران در زیر ترسیم شده است.
*خطوط راهنما برای تحلیل عاملی، تحلیل مسیر و تحلیل مدل معادلات ساختاری
1- تحلیل عاملی به دو دسته کلی تحلیل عاملی اکتشافی (EFA) و تحلیل عاملی تأییدی (CFA) دستهبندی میشود. در نوع اول فرضیهای وجود ندارد و تنها موقعی موفقیتآمیز است که گویههایی که در زیر یک عامل میآیند یک مفهوم (روح) مشترک داشته باشند و اگر چنین مفهوم مشترکی وجود نداشته باشد تحلیل عاملی اکتشافی نباید صورت گیرد.
2- تحلیل عاملی تأییدی که مبتنی بر فرضیه ساخته میشود همواره باید بعد از تحلیل عاملی اکتشافی صورت گیرد. این دو نوع تحلیل عاملی باید روی دو نمونه مجزا (و نه خطایی آشکار که در پژوهشهای ایران به فراوانی دیده میشود) نه روی یک نمونه انجام شود؛ چراکه مشخص است که روی همان دادهها، شاخصهای برازش مطلوب خواهند بود و نمیتوان فرضیه را تأیید کرد.
3- اگر فردی ابرازی را طراحی میکند حتماً باید روی آن تحلیل عاملی اکتشافی انجام دهد. اگر نتیجه موفقیتآمیز نبود تحلیل عاملی نباید گزارش شود؛ اما فرد میتواند با شیوههای معمول آماری فرضیههای خود را دنبال کند. بسیاری از سازهها، سالها در تحلیل عاملی موفق نبودهاند، این به معنای رد آن سازهها نیست. این نشاندهنده تفوق فلسفه علم کوه بر پوپر است.
4- اگر زیرسازهها با یکدیگر رابطه (بهصورت نظری) دارند باید از تحلیل مایل استفاده کنند؛ و گرنه (در صورت استقلال) باید از تحلیل متعامد استفاده شود.
5- هرگاه ابزاری از جامعه دیگر (مثلاً انگلیسی) ترجمه میشود باید تحلیل عامل تأییدی (CFA) با دادههای جامعه ایرانی انجام شود.
6- تحلیل مسیر که توسط سؤال رایت (در مطالعات ژنتیک) در دهه چهل قرن بیستم انجام شد در یک مدل یک طرفه (که لزوماً به معنی علیت فلسفی نیست) به محاسبه ضرایب مسیر بر مبنای ضریب همبستگی منجر میشود. هر چه متغیرها در تحلیل مسیر بیشتر و پیچیدهتر باشند این ضرایب مسیر از معادلات ریاضی پیچیدهتری به دست میآیند. یکی گرفتن ضریب همبستگی و ضریب مسیر یک تقلب آشکار است که داوران میتوانند بهسادگی آن را کشف کنند.
7- تحلیل عاملی که توسط اسپیرمن در آغاز قرن بیستم به وجود آمد در ترکیب با تحلیل مسیر در پایان قرن بیستم به مدل معادلات ساختاری (SEM) انجامید. در این مدل شاخصهای برازش به معنی تأیید فرضیههای محقق نیست. محقق باید از طرحهای پژوهشی قوی در کنار پیشینهای قوی برای ساخت فرضیهها استفاده کند و نداشتن این پیشینه یا طرح نباید منجر به تأیید فرضیه فقط به کمک شاخصهای برازش شود.
8- پژوهشگرانی که به مورد هفتم واقف نیستند بدون استفاده از طرحهای پژوهشی قوی یا پیشینه مناسب و فقط بهصرف شاخصهای برازش ممکن است فرضیهای را تأیید کنند. نویسنده این مقاله هیچ امکان دیگری را در پژوهشهای ایرانی نیافته است که بهاندازه این درک نادرست به مقالههای نادرست انجامیده باشد. این پژوهشگران تصور میکنند کافی است پیشینههایی برای متغیرهای تحلیل میانجی ذکر کنند و بقیه کارها را شاخصهای برازش انجام خواهد داد. همان ایده دوربین عکاسی کداک:
You press the bottom. We do the rest
9- پژوهشگرانی که به مورد هفتم واقف هستند ولی پیشینه مناسب را نمییابند، ممکن است به خلق این پیشینه بپردازند. این مقالهها حتماً باید ریتراکت شوند. بنابراین اگر داور به این پیشینه مشکوک شد باید آنها را شناسایی کند. این نوع پژوهشگران از شعار عبری استفاده میکنند که در اقتصاد مشهور شد.
Create out of Nothing
*** خطوط راهنما برای تحلیل عاملی اکتشافی و تأییدی
1- برخی از روشهای آماری (مثل تحلیل عاملی اکتشافی، رگرسیون چندگانه، تحلیل واریانس با آزمونهای تعقیبی پسینی) رویکردهای اکتشافی در آمار هستند. آنها فرضیه ندارند و نوشتن فرضیه برای آنها کاملاً ساختگی است.
2- برخی دیگر از روشهای آماری (مثل تحلیل عاملی تأییدی، رگرسیونهای سلسله مراتبی، تحلیل واریانس با آزمونهای تعقیبی پیشینی) رویکردهای تأییدی در آمار هستند. آنها برای تأیید فرضیه مورداستفاده قرار میگیرند.
3- مدل معادلات ساختاری یک رویکرد تأییدی است.
4- همه روشهای تأییدی یا باید دارای طرحهای قوی (مثل طرحهای طولی یا آزمایشی) باشند یا دارای پیشینه بسیار قوی باشند.
5- همه مدلهای ریاضی میتوانند (رویکرد اکتشافی) و یا (رویکرد تعدیلی، یکی از انواع رویکردهای تأییدی) باشند.
6- معروفترین رویکردهای تأییدی شامل رویکرد تعدیلی، میانجی، فرونشان، همرس است.
7- شاخصهای برازش میتوانند همزمان همه این رویکردها را تأیید کنند. آنها فقط برازش دادهها با مدلها را تأییدی میکنند و این به معنی تأیید فرضیهها در آن مدلها نیست.
خطوط راهنما برای رگرسیونهای چندگانه، تفکیکی و سلسله مراتبی
1- در رگرسیون چندگانه فرضیه نباید نوشته شود. همبستگیهای ساده فرضیه محسوب نمیشوند و جملاتی از قبیل اینکه همبستگیهای بین متغیرهای پیشبین، متغیر ملاک را پیشبینی میکند فرضیه نیست؛ زیرا معلوم نیست این ترکیب بین کدام متغیرهاست و بنابراین ابطالپذیر نیست. از این نوع رگرسیون فقط در مرحله اول یک پژوهش و برای یک جستوجوی اولیه میتوان استفاده کرد. گاهی ممکن است رگرسیون ساده یا همبستگی ساده در موارد نادر فرضیه پژوهشی باشد، مانند پژوهش عریضی و دژبان (2015) که در آن همبستگی بین دو موقعیت از یک سنجش که بهصورت گذشتهنگر مدنظر است. هدف آن پیوستگی بین این دو نوع موقعیت زمانی از یک سنجش است که در پژوهشهای گذشتهنگر وجود دارد.
2- عکس رگرسیون چندگانه، رگرسیون سلسله مراتبی دارای فرضیه و بر مبنای نظریههای استوار انجام میگیرد. ترتیب ورود متغیرها را برخلاف رگرسیون چندگانه پژوهشگر تعیین میکند. مجله باید در این زمینه پژوهشگران را هدایت کند تا مقالات عمیقتری بر مبنای رگرسیون سلسله مراتبی بنویسند. تابهحال هیچ مقاله با این سبک در مجله گزارش نشده است.
3- برخلاف رگرسیون چندگانه که ها یک متغیر y را پیشبینی میکند در رگرسیونهای چند متغیره چند متغیر وابسته پیشبینی میشود پژوهشگران با این شیوه تحلیل آماری آشنایی نداشته و در مجله رفاه اجتماعی گزارش نشده است. تحلیل همبستگی متعارف که نوعی از آن است نیز برای پژوهشگرانی که آشنایی فنی با علم آماری ندارند کمتر استفاده میشود. یک شیوه برای مجموعه هایی که ها را پیشبینی میکند تبدیل آن به J رگرسیون مجزاست که در هر یک ها یک y را پیشبینی میکند. این شیوه تحلیل به دلیل آن که روابط را همزمان مدنظر قرار نمیدهد دارای اشکال است. پژوهشگران گاهی به حدی با رگرسیون چندگانه ناآشنا هستند که آن را رگرسیون چند متغیره مینامند.
4- همبستگیهای تفکیکی میتوانند به پژوهشگر کمک کنند تا رابطه بین دو متغیر x و y را بهصورت خالص مشخص کند. بنابراین هرگاه این همبستگی بالاتر از 7/ 0 باشد به معنی آن است که متغیرها درواقع مربوط به فقط یک متغیر است.
5- همه مراحل مدل معادلات ساختاری باید بهدقت گزارش شود. بهبود مدل پیشنهادی اهمیت دارد اما مهمتر از آن مرحله مشخص کردن رابطه بین متغیرهاست که نیاز به یک پیشینه قوی دارد.
یادداشت (1): هنگامیکه دو متغیر دارای توزیع نرمال باشند، جمع آن دو متغیر بنا به یک قضیه در آمار همواره دارای توزیع نرمال است. در توزیع نرمال فاصله اطمینانی که برای فرضیه آزمایی طبق الگوی نیمن پیرسون ساخته میشود حول مقدار آماره در نمونه متقارن است و با افزودن و کاستن حاصلضرب خطای معیار اندازهگیری (SEM) در مقدار به دست میآید. در تحلیل میانجی با نمودار زیر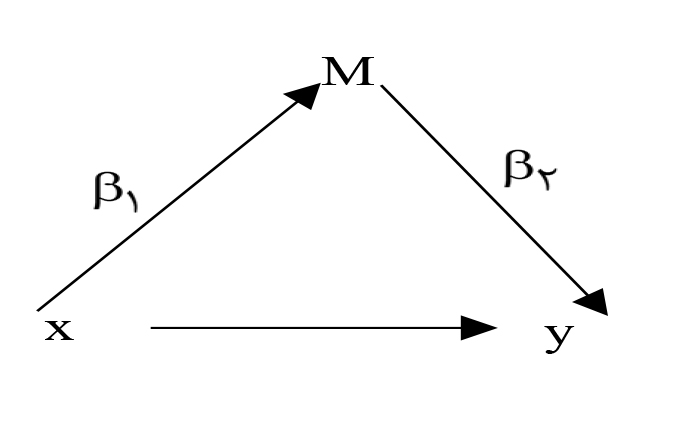
اثر غیرمستقیم (میانجی) حاصل ضریب (و نه حاصل جمع) دو ضریب مسیر و است. حتی اگر هر دو دارای توزیع نرمال باشند حاصل ضریب آنها معلوم نیست که نرمال باشد. به همین دلیل به جای روش معمول در توزیع نرمال (و آماره پارامتریک) که در ابتدای تحلیل میانجی t سوبل بود، از روشهای بازنمونهگیری مثل جک نایف و بوت استراپ استفاده میکنند.
ضمیمه
ملاحظات اخلاقی
نویسنده هشت ماه زمان برای مرور مقالات و همه منابع آن اختصاص داده است.
منابع مالی
این مرور انتقادی حامی مالی نداشته است.
تعارض منافع
این مرور با هیچ یک از آثار مؤلف همپوشی نداشته است.
متابعت از اخلاق پژوش
اصل انصاف در اخلاق سنگ زیربنای مقاله مرور انتقادی بوده است.
متن کامل: (2266 مشاهده)
مقدمه
جامعه برای هر نام گنجهای گرد میآورد که هزار اشتباه از دل آن برمیآید.
مارسل پروست، طرف گرمانت، جستجوی روزگار ازدسترفته، صفحه 577 متن گالیمار
برالکیورن مهمترین چالش محققان علوم اجتماعی را وضوح بخشیدن به معنی و قصد در بطن کلماتی میداند که به کار میبرند. هنگامیکه در مورد یک رابطه سخن گفته میشود معنی آن چیست؟ بهعبارتدیگر وقتی از تحلیل رابطهای سخن میگوییم درباره چه موضوعی حرف میزنیم؟ اگر کلمهای مثل رابطه بهصورت نادرستی درک و فهمیده شود ممکن است بهنوعی جریان غالب تبدیل شود که در مقابل علم قرار گیرد. در پژوهشهای آزمایشی مسئله بسیار ساده است: مداخله تأثیری بر جای مینهد که از پیشآزمون تا پسآزمون باید سنجیده شود. روشهای آماری هم مشخص است. اما در پژوهشهای رابطهای مسئله بسیار پیچیده است. افلاطون به این موضوع توجه کرده بود که اگر معنی کلمهای تغییر کند و از حقیقت مفهوم آن فاصله بگیرد طرفداران فن خطابه (ریطوریقا) ممکن است از فنون پیروز شدن در بحث استفاده کنند و پاسخهای درست را به محاق ببرند (گروس، 1989).
ویتگنشتاین از اصطلاح زبان خصوصی استفاده میکرد. ممکن است هر فرد مانند فرد دچار اسکیزوفرنی زبانی خصوصی ابداع کند که متناظر با واقعیت نباشد. ازنظر ویتگنشتاین کار فلسفه، درمان این اسکیزوفرنی زبانی و ازنظر افلاطون دورکردن از چشم مشاطهگران بازار خطابه است. نمونهای از این زبان خصوصی را نزد هامپتی دامپتی در «آلیس آن سوی آینه» میبینیم که واژهای را در جملهای به کار میبرد و آلیس میخواهد که معنی آن را توضیح دهد و درمییابد که ازنظر هامپتی دامپتی به معنی دیگر و دلبخواه بهکاررفته است. آلیس اعتراض میکند، اما هامپتی دامپتی میگوید وقتی کلمهای را به زبان میآورم، معنیاش درست همان چیزی است که دلم میخواهد باشد، نه بیش و نه کم. این همان زبان خصوصی است که از ملاکهای دقیق و عینی بیرونی تبعیت نمیکند.
مولوی هم به این زبان خصوصی اشاره میکند: ایبسا دو ترک چون بیگانگان. هرچند زبان تکلم آنها یکسان است، آنها زبان را بهصورت دلبخواه به کار میبرند و این سبب بیگانگی آنها با هم میشود. آن چه در عین تفاوت زبان تکلم، همزبانی ایجاد میکند (ایبسا هندو و ترک همزبان) زبان علم و بهخصوص ریاضی است که مقاله حاضر با توجه ویژه به آن در علم آمار نوشته شده است.
جامعه برای هر نام گنجهای گرد میآورد که هزار اشتباه از دل آن برمیآید.
مارسل پروست، طرف گرمانت، جستجوی روزگار ازدسترفته، صفحه 577 متن گالیمار
برالکیورن مهمترین چالش محققان علوم اجتماعی را وضوح بخشیدن به معنی و قصد در بطن کلماتی میداند که به کار میبرند. هنگامیکه در مورد یک رابطه سخن گفته میشود معنی آن چیست؟ بهعبارتدیگر وقتی از تحلیل رابطهای سخن میگوییم درباره چه موضوعی حرف میزنیم؟ اگر کلمهای مثل رابطه بهصورت نادرستی درک و فهمیده شود ممکن است بهنوعی جریان غالب تبدیل شود که در مقابل علم قرار گیرد. در پژوهشهای آزمایشی مسئله بسیار ساده است: مداخله تأثیری بر جای مینهد که از پیشآزمون تا پسآزمون باید سنجیده شود. روشهای آماری هم مشخص است. اما در پژوهشهای رابطهای مسئله بسیار پیچیده است. افلاطون به این موضوع توجه کرده بود که اگر معنی کلمهای تغییر کند و از حقیقت مفهوم آن فاصله بگیرد طرفداران فن خطابه (ریطوریقا) ممکن است از فنون پیروز شدن در بحث استفاده کنند و پاسخهای درست را به محاق ببرند (گروس، 1989).
ویتگنشتاین از اصطلاح زبان خصوصی استفاده میکرد. ممکن است هر فرد مانند فرد دچار اسکیزوفرنی زبانی خصوصی ابداع کند که متناظر با واقعیت نباشد. ازنظر ویتگنشتاین کار فلسفه، درمان این اسکیزوفرنی زبانی و ازنظر افلاطون دورکردن از چشم مشاطهگران بازار خطابه است. نمونهای از این زبان خصوصی را نزد هامپتی دامپتی در «آلیس آن سوی آینه» میبینیم که واژهای را در جملهای به کار میبرد و آلیس میخواهد که معنی آن را توضیح دهد و درمییابد که ازنظر هامپتی دامپتی به معنی دیگر و دلبخواه بهکاررفته است. آلیس اعتراض میکند، اما هامپتی دامپتی میگوید وقتی کلمهای را به زبان میآورم، معنیاش درست همان چیزی است که دلم میخواهد باشد، نه بیش و نه کم. این همان زبان خصوصی است که از ملاکهای دقیق و عینی بیرونی تبعیت نمیکند.
مولوی هم به این زبان خصوصی اشاره میکند: ایبسا دو ترک چون بیگانگان. هرچند زبان تکلم آنها یکسان است، آنها زبان را بهصورت دلبخواه به کار میبرند و این سبب بیگانگی آنها با هم میشود. آن چه در عین تفاوت زبان تکلم، همزبانی ایجاد میکند (ایبسا هندو و ترک همزبان) زبان علم و بهخصوص ریاضی است که مقاله حاضر با توجه ویژه به آن در علم آمار نوشته شده است.
آلیس در گذر از آینه لوئیس کارول
هدف این مقاله نشان دادن این نکته است که بسیاری از پژوهشگرانی که مقالههای آنها پژوهش رابطهای است همان الگوی هامپتی دامپتی را دارند و سؤال ما همان است که آلیس گفت: آیا از دست تو برمیآید کاری کنی که کلمات معنی دیگری داشته باشند؟
هایلیر (2012) در مقاله «ایجاد معنا، حکمرانی بر تغییر: ملاقات ویتگنشتاین و هامپتی دامپتی» به موقعیتی اشاره میکند که در آن، فلسفه مقابل خطابه قرار میگیرد. در فلسفه اصل بر کاربرد درست مفاهیم است، درحالیکه در خطابه هدف پیروزی به هر قیمت است؛ بهخصوص با زیر پا گذاشتن حقیقت.
ارسطو کاربرد درست منطق را در ارغنون و کاربرد نادرست آن را در فن خطابه بررسی کرده است. همین هدف در آثار لیوتار (1984) و کوهن (2000) تبدیل به اصطلاح بازی زبانی میشود که بهنوعی بازی قدرت است. هدف مقاله حاضر نجات دادن دادههای رابطهای از حاکمیت هامپتی دامپتی است. این مقاله مرور انتقادی بر مقالههایی است که دادههای رابطهای را بهعنوان دادههای خود انتخاب کردهاند، یعنی شیوه تحقیق آنها روش رابطهای بوده است. جملهای که بر پیشانی مقدمه از مارسل پروست آمد بهخوبی با وضعیت دادههای رابطهای هماهنگ است: در زیر این نام گنجهای وجود دارد که هزاران اشتباه از دل آن برمیآید. مسئله مهم این است که این اشتباهات در دسترستر از انتخابهای صحیح و درست است. در این گنجه هزاران مقاله بدون پشتوانه علمی گرد آمده است. یکی از دلایل آن پیچیدگی مفهوم همبستگی است. سایمون، اقتصاددان بزرگ و برنده جایزه نوبل، در مقاله مشهور خود در مورد همبستگی خیالی از رابطههایی سخن به میان آورده است که معنی خاصی نداشته و صرفاً از طریق متغیر سومی به هم مربوط شدهاند.
ولی اشکال برخی پژوهشها گاهی از همبستگی خیالی فراتر میرود و اموری که هیچ نسبتی با یکدیگر ندارند و حتی در مقابل هم قرار دارند، دارای رابطهای همافزا نشان داده شدهاند. مثلاً سبکهای دلبستگی ایمن و اجتنابی را که کاملاً در مقابل یکدیگر قرار دارند میتوان از طریق پرسشنامهها بهصورت نموی در یک رگرسیون چندگانه قرار داد، انگار که در وجود افراد این دو نوع دلبستگی با یکدیگر جمع میشود. کامپیوتر چون دارای قوه تمیز نیست دادههایی را که به آن وارد میشود طبق الگویی که در آمار معمولاً حداقل مجذورات یا بیشینه احتمالی است بر یکدیگر میافزاید.
این تصور که ماشین، حقیقت را به کمک محاسبه آشکار میکند توسط جان سرل به چالش کشیده شده است. مقاله او در مورد انواع ماشینهای تورینگ (مثل SCHRDLU) نوشته شده است اما میتوان عیناً آن را به ماشینهای نرمافزاری مثل LISREI و AMOS گسترش داد. در بخش منابع مورد چهارم به آن پرداختهام. اصلاح بینش در مورد پژوهش رابطهای را میتوان از طریق تحلیل خطاهایی که در پژوهشها وجود دارد بهخوبی آموزش داد و یکی از اهداف مقاله حاضر نیز دقیقاً همین است.
نشان خواهیم داد که در پژوهشهایی که از مجله نقل خواهد شد این زبان غیردقیق منجر به تحلیل نادرست یافتهها و نتیجه نادرست شده است. هنری دیوید ثورو مینویسد که اسکندر کلمههای مکتوب را همراه خود بهمثابه راهنما برای فتوحات خود میبرد. این کلمات از ایلیاد انتخاب شده و در صندوقچه گرانبها قرار داده شده بود. با وجود آنکه عبدالملکیان شاعر خواسته بود، جهان کلمات را به شاعران بسپاریم، اما در جهان علم باید مثل افلاطون عمل کنیم و شاعران را از این جهان بیرون کنیم؛ چون در زبان علمی کلمات با زبان شاعرانه متفاوت است و دقت بسیار بیشتری نیاز دارد. در بحث از منابعی که موردانتقاد قرار گرفتهاند به این موضوع بیشتر خواهیم پرداخت. نشان خواهیم داد که استفاده نادرست از زبان نقش زیادی در تأیید مدلهایی دارد که اصولاً نادرست هستند.
در این مرور انتقادی به ضرورت به معادلات ریاضی ارجاع داده شده است تا از طریق این معادلات تصویر کلیتری از پژوهشهای رابطهای برای خوانندگان مقاله ایجاد شود. باید توجه کرد که مانند بقیه مقالات مرور انتقادی، خوانندگان این مقاله باید مرتباً به مقالاتی که در این مقاله به آنها ارجاع شده است نگاه کنند. در هر مورد به آن مقالهها ارجاع شده است تا خواننده بتواند مقاله موردنظر را به سهولت یافته و نقدهای ارائهشده را دریابد.
ذکر نکتهای بیمناسبت نخواهد بود: مارک کاک هنگامیکه کتاب گرانقدر استقلال آماری در احتمالات، آنالیز و نظریه اعداد را نوشت بیان کرد که هدف او آن بوده است که نشان دهد چگونه مفهوم استقلال آماری در همه رشتههای دیگر حضور دارد و ازاینرو یک دید یکپارچه نسبت به این مفهوم در ریاضی ایجاد کند.
گال بورگ و گال نیز پژوهشهای رابطهای را در مقابل پژوهشهای آزمایشی بهصورت یک ساختار کلی تعریف کردهاند که نشاندهنده این رویکرد سطح بالاتر است. در این مرور انتقادی هم انواع مدلهای رگرسیون و میانجی و تعدیلی و کورایانس و لجستیک و رگرسیون سلسله مراتبی و طرحهای علی پس-رویدادی شکلهای گوناگون پژوهش رابطهای است. باید توجه کرد که برخی از این روشها بهصورت تحلیلهای اکتشافی و برخی بهصورت تحلیلهای تأییدی هستند. عدم درک درست مدل معادلات ساختاری و شاخصهای برازش عدهای را به این گمان انداخته است که میتوانند به کمک این ابزارها پژوهشهای سادهای بدون پیشینه و بدون فرضیه و فقط با جمعآوری دادهها پدید آورند. این خطا هم طرحهای اکتشافی (مثل مدلهای رگرسیون چندگانه) و هم طرحهای تأییدی (مثل میانجی و تعدیلی) را در برمیگیرد. در اولی فرضیههایی طرح میشود بدون آنکه توجه شود این نوع طرحها بدون فرضیهاند و در گروه دوم این خطا که میتوان با شاخص برازش فرضیههایی که بهدرستی و با پیشینه توجیه نشدهاند را تأیید (یا رد) کرد.
مقالههایی که در این مقاله نقد شدهاند در جدول (1) ضمیمه آورده شده است.
1- از رابطه ساده بین دو متغیر تا همبستگی تفکیکی بین دو متغیر
رابطه ساده معمولاً نمیتواند فرضیه پژوهش باشد. گاهی در مجله رابطههای ساده بهصورت فرضیه در نظر گرفته شده است. رابطه ساده فقط مرحله اول از شروع رگرسیون چندگانه است که متغیرهای پیشبین در جایی که آنها معنی دارند در معادله رگرسیون چندگانه وارد میشوند و اگر معنیدار نبودند از رگرسیون حذف میشوند.
گاهی رابطه ساده بین متغیرها بهصورت غیرمعقولی است که پذیرفتنی نیست. قائد رحمتی و ضیائی این فرضیه را موردسنجش قرار دادند که بین جمعیت شهرها و کشف مواد مخدر رابطه وجود دارد. این رابطه ساده که فقط بهصورت ضریب همبستگی گزارش شده است بر پایه دادههای آرشیوی به دست آمده است که در آن هر دو متغیر در آرشیو وجود دارند. در این مطالعه، همبستگیها نادرست هستند. نگارنده بهصورت دستی به محاسبه آنها پرداخته و اعداد دیگری را به دست آورده است.
در جدول 6 که اولین جدول غیر از دادههای آرشیوی است همبستگی بین جمعیت و کشف مرفین 992/ 0 و بین جمعیت و کشف هروئین 087/ 0 (ص 109) گزارش شده است. غیرقابلتوجیه است که این همه جمعیت در کشف مرفین نقش داشته و در کشف هروئین هیچ نقشی نداشته باشد. برخی جملهها در متن مقاله هست که یکسره غلط است. مثلاً هم در عنوان و هم در متن (ص 109) آمده است که سطح معنیداری بیش از 05/ 0 است و لذا فرضیه H0 رد میشود یا معنیداری کمتر از 01/ 0 به معنی همبستگی دوطرفه و معنیداری کمتر از 05/ 0 به معنی یک طرفه است.
در پژوهش زارع و زارع (2015) در مورد رابطه شخصیت، سرمایه اجتماعی و سرمایه فرهنگی نیز از رگرسیون چندمتغیره سخن گفته شده است. ازآنجاکه هم سرمایه و هم شخصیت متغیرهای چندبعدی هستند کاربرد رگرسیون چندمتغیره درست است؛ ولی آنها در عمل از رگرسیون چندگانه استفاده کردهاند؛ یعنی متغیر وابسته (سرمایه اجتماعی) را هر بار با یکی از مؤلفهها در نظر گرفتهاند.
همچنین در پژوهش آنان رابطه تعاملی جنسیت و موفقیت مهم است که نادیده گرفته شده است. درواقع این همان فرضیه هورنر است که به آن توجهی نشده است. معمولاً انسانها دو انگیزش میل به موفقیت و ترس از شکست را دارند. هورنر برای نخستین بار دریافت که زنان ترس از موفقیت را نیز دارا هستند؛ به دلیل اینکه موفقیت در آنان به دو عامل موفقیت در زندگی و موفقیت در شغل مربوط است و بسیاری از زنان نگران آن هستند که موفقیت در تحصیل و شغل سبب به تعویق افتادن در ازدواج و تشکیل زندگی شود. این موقعیتی است که رگرسیون سلسله مراتبی و اثر تعدیلی اهمیت بسیار بیشتری از رگرسیون چندگانه دارد.
در مقاله غفاری و همکاران (2019) سه متغیر سرمایه اقتصادی، سرمایه نهادی و سرمایه اجتماعی به لحاظ مفهومی متفاوتاند، ولی به لحاظ مختصات روانسنجی چنین نیستند. ضرایب همبستگی نقش مهمی در نشاندادن تمایز متغیرها دارد. ازآنجاکه متغیرها همواره با متغیرهای دیگری رابطه دارند از طریقه همبستگی تفکیکی میتوان رابطه بین دو متغیر را مستقل از متغیر سوم تعیین کرد. ازآنجاکه حد 7/ 0 برای پایایی متغیر مطلوب است، میتوان حداکثر تا این حد دو متغیر را به لحاظ مفهومی متفاوت در نظر گرفت. در مقاله مزبور سرمایه نهادی و سرمایه اجتماعی به لحاظ روانسنجی یک متغیر است و تأکید متن مقاله آنها استفاده از زبان برای توجیه این مطلب است که آنها دو سازه مختلفاند.
اجازه دهید دادههای جدول 5 صفحه 40 مقاله آنها را مجدداً تحلیل کنیم. این جدول مربوط به ضرایب همبستگی سرمایه اقتصادی، سرمایه نهادی و سرمایه اجتماعی است. ضرایب پایایی به معنای ضریب همبستگی یک متغیر با خود ( ) و ضرایب روایی به معنی ضریب همبستگی یک متغیر با متغیر دیگر ( ) است. درواقع این دو ضریب مشابه دوقلوها و افراد عادی هستند. اگر همبستگی یک متغیر با متغیر دیگر از 7/ 0 بیشتر باشد در آن صورت این شک وجود دارد که آن دو متغیر درواقع یک متغیر باشند، که به دو گونه مختلف بیان شده است. میتوانیم از دادههای جدول 5 ضرایب همبستگی تفکیکی را از فرمول زیر محاسبه کنیم.
(معادله 1)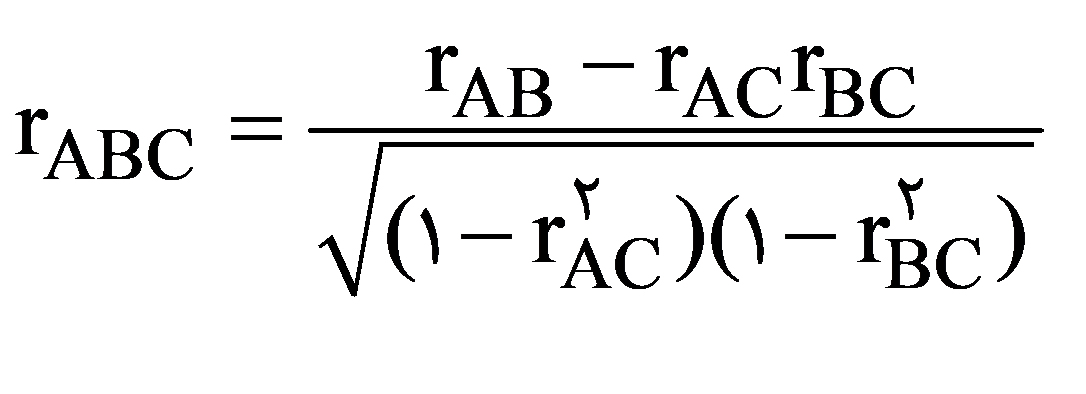
که ضریب همبستگی تفکیکی است یعنی همبستگی بین A و B را میسنجد هنگامیکه C از آن جدا شده باشد. با توجه به این فرمول ضریب همبستگی تفکیکی سرمایه اجتماعی و سرمایه نهادی برابر 96/ 0 و ضریب همبستگی سرمایه اقتصادی و اجتماعی برابر 62/ 0 به دست میآید که ضریب تعیین آنها برابر 92/ 0 و 38/ 0 است. میتوان آن را با نمودار زیر نشان داد:
هایلیر (2012) در مقاله «ایجاد معنا، حکمرانی بر تغییر: ملاقات ویتگنشتاین و هامپتی دامپتی» به موقعیتی اشاره میکند که در آن، فلسفه مقابل خطابه قرار میگیرد. در فلسفه اصل بر کاربرد درست مفاهیم است، درحالیکه در خطابه هدف پیروزی به هر قیمت است؛ بهخصوص با زیر پا گذاشتن حقیقت.
ارسطو کاربرد درست منطق را در ارغنون و کاربرد نادرست آن را در فن خطابه بررسی کرده است. همین هدف در آثار لیوتار (1984) و کوهن (2000) تبدیل به اصطلاح بازی زبانی میشود که بهنوعی بازی قدرت است. هدف مقاله حاضر نجات دادن دادههای رابطهای از حاکمیت هامپتی دامپتی است. این مقاله مرور انتقادی بر مقالههایی است که دادههای رابطهای را بهعنوان دادههای خود انتخاب کردهاند، یعنی شیوه تحقیق آنها روش رابطهای بوده است. جملهای که بر پیشانی مقدمه از مارسل پروست آمد بهخوبی با وضعیت دادههای رابطهای هماهنگ است: در زیر این نام گنجهای وجود دارد که هزاران اشتباه از دل آن برمیآید. مسئله مهم این است که این اشتباهات در دسترستر از انتخابهای صحیح و درست است. در این گنجه هزاران مقاله بدون پشتوانه علمی گرد آمده است. یکی از دلایل آن پیچیدگی مفهوم همبستگی است. سایمون، اقتصاددان بزرگ و برنده جایزه نوبل، در مقاله مشهور خود در مورد همبستگی خیالی از رابطههایی سخن به میان آورده است که معنی خاصی نداشته و صرفاً از طریق متغیر سومی به هم مربوط شدهاند.
ولی اشکال برخی پژوهشها گاهی از همبستگی خیالی فراتر میرود و اموری که هیچ نسبتی با یکدیگر ندارند و حتی در مقابل هم قرار دارند، دارای رابطهای همافزا نشان داده شدهاند. مثلاً سبکهای دلبستگی ایمن و اجتنابی را که کاملاً در مقابل یکدیگر قرار دارند میتوان از طریق پرسشنامهها بهصورت نموی در یک رگرسیون چندگانه قرار داد، انگار که در وجود افراد این دو نوع دلبستگی با یکدیگر جمع میشود. کامپیوتر چون دارای قوه تمیز نیست دادههایی را که به آن وارد میشود طبق الگویی که در آمار معمولاً حداقل مجذورات یا بیشینه احتمالی است بر یکدیگر میافزاید.
این تصور که ماشین، حقیقت را به کمک محاسبه آشکار میکند توسط جان سرل به چالش کشیده شده است. مقاله او در مورد انواع ماشینهای تورینگ (مثل SCHRDLU) نوشته شده است اما میتوان عیناً آن را به ماشینهای نرمافزاری مثل LISREI و AMOS گسترش داد. در بخش منابع مورد چهارم به آن پرداختهام. اصلاح بینش در مورد پژوهش رابطهای را میتوان از طریق تحلیل خطاهایی که در پژوهشها وجود دارد بهخوبی آموزش داد و یکی از اهداف مقاله حاضر نیز دقیقاً همین است.
نشان خواهیم داد که در پژوهشهایی که از مجله نقل خواهد شد این زبان غیردقیق منجر به تحلیل نادرست یافتهها و نتیجه نادرست شده است. هنری دیوید ثورو مینویسد که اسکندر کلمههای مکتوب را همراه خود بهمثابه راهنما برای فتوحات خود میبرد. این کلمات از ایلیاد انتخاب شده و در صندوقچه گرانبها قرار داده شده بود. با وجود آنکه عبدالملکیان شاعر خواسته بود، جهان کلمات را به شاعران بسپاریم، اما در جهان علم باید مثل افلاطون عمل کنیم و شاعران را از این جهان بیرون کنیم؛ چون در زبان علمی کلمات با زبان شاعرانه متفاوت است و دقت بسیار بیشتری نیاز دارد. در بحث از منابعی که موردانتقاد قرار گرفتهاند به این موضوع بیشتر خواهیم پرداخت. نشان خواهیم داد که استفاده نادرست از زبان نقش زیادی در تأیید مدلهایی دارد که اصولاً نادرست هستند.
در این مرور انتقادی به ضرورت به معادلات ریاضی ارجاع داده شده است تا از طریق این معادلات تصویر کلیتری از پژوهشهای رابطهای برای خوانندگان مقاله ایجاد شود. باید توجه کرد که مانند بقیه مقالات مرور انتقادی، خوانندگان این مقاله باید مرتباً به مقالاتی که در این مقاله به آنها ارجاع شده است نگاه کنند. در هر مورد به آن مقالهها ارجاع شده است تا خواننده بتواند مقاله موردنظر را به سهولت یافته و نقدهای ارائهشده را دریابد.
ذکر نکتهای بیمناسبت نخواهد بود: مارک کاک هنگامیکه کتاب گرانقدر استقلال آماری در احتمالات، آنالیز و نظریه اعداد را نوشت بیان کرد که هدف او آن بوده است که نشان دهد چگونه مفهوم استقلال آماری در همه رشتههای دیگر حضور دارد و ازاینرو یک دید یکپارچه نسبت به این مفهوم در ریاضی ایجاد کند.
گال بورگ و گال نیز پژوهشهای رابطهای را در مقابل پژوهشهای آزمایشی بهصورت یک ساختار کلی تعریف کردهاند که نشاندهنده این رویکرد سطح بالاتر است. در این مرور انتقادی هم انواع مدلهای رگرسیون و میانجی و تعدیلی و کورایانس و لجستیک و رگرسیون سلسله مراتبی و طرحهای علی پس-رویدادی شکلهای گوناگون پژوهش رابطهای است. باید توجه کرد که برخی از این روشها بهصورت تحلیلهای اکتشافی و برخی بهصورت تحلیلهای تأییدی هستند. عدم درک درست مدل معادلات ساختاری و شاخصهای برازش عدهای را به این گمان انداخته است که میتوانند به کمک این ابزارها پژوهشهای سادهای بدون پیشینه و بدون فرضیه و فقط با جمعآوری دادهها پدید آورند. این خطا هم طرحهای اکتشافی (مثل مدلهای رگرسیون چندگانه) و هم طرحهای تأییدی (مثل میانجی و تعدیلی) را در برمیگیرد. در اولی فرضیههایی طرح میشود بدون آنکه توجه شود این نوع طرحها بدون فرضیهاند و در گروه دوم این خطا که میتوان با شاخص برازش فرضیههایی که بهدرستی و با پیشینه توجیه نشدهاند را تأیید (یا رد) کرد.
مقالههایی که در این مقاله نقد شدهاند در جدول (1) ضمیمه آورده شده است.
1- از رابطه ساده بین دو متغیر تا همبستگی تفکیکی بین دو متغیر
رابطه ساده معمولاً نمیتواند فرضیه پژوهش باشد. گاهی در مجله رابطههای ساده بهصورت فرضیه در نظر گرفته شده است. رابطه ساده فقط مرحله اول از شروع رگرسیون چندگانه است که متغیرهای پیشبین در جایی که آنها معنی دارند در معادله رگرسیون چندگانه وارد میشوند و اگر معنیدار نبودند از رگرسیون حذف میشوند.
گاهی رابطه ساده بین متغیرها بهصورت غیرمعقولی است که پذیرفتنی نیست. قائد رحمتی و ضیائی این فرضیه را موردسنجش قرار دادند که بین جمعیت شهرها و کشف مواد مخدر رابطه وجود دارد. این رابطه ساده که فقط بهصورت ضریب همبستگی گزارش شده است بر پایه دادههای آرشیوی به دست آمده است که در آن هر دو متغیر در آرشیو وجود دارند. در این مطالعه، همبستگیها نادرست هستند. نگارنده بهصورت دستی به محاسبه آنها پرداخته و اعداد دیگری را به دست آورده است.
در جدول 6 که اولین جدول غیر از دادههای آرشیوی است همبستگی بین جمعیت و کشف مرفین 992/ 0 و بین جمعیت و کشف هروئین 087/ 0 (ص 109) گزارش شده است. غیرقابلتوجیه است که این همه جمعیت در کشف مرفین نقش داشته و در کشف هروئین هیچ نقشی نداشته باشد. برخی جملهها در متن مقاله هست که یکسره غلط است. مثلاً هم در عنوان و هم در متن (ص 109) آمده است که سطح معنیداری بیش از 05/ 0 است و لذا فرضیه H0 رد میشود یا معنیداری کمتر از 01/ 0 به معنی همبستگی دوطرفه و معنیداری کمتر از 05/ 0 به معنی یک طرفه است.
در پژوهش زارع و زارع (2015) در مورد رابطه شخصیت، سرمایه اجتماعی و سرمایه فرهنگی نیز از رگرسیون چندمتغیره سخن گفته شده است. ازآنجاکه هم سرمایه و هم شخصیت متغیرهای چندبعدی هستند کاربرد رگرسیون چندمتغیره درست است؛ ولی آنها در عمل از رگرسیون چندگانه استفاده کردهاند؛ یعنی متغیر وابسته (سرمایه اجتماعی) را هر بار با یکی از مؤلفهها در نظر گرفتهاند.
همچنین در پژوهش آنان رابطه تعاملی جنسیت و موفقیت مهم است که نادیده گرفته شده است. درواقع این همان فرضیه هورنر است که به آن توجهی نشده است. معمولاً انسانها دو انگیزش میل به موفقیت و ترس از شکست را دارند. هورنر برای نخستین بار دریافت که زنان ترس از موفقیت را نیز دارا هستند؛ به دلیل اینکه موفقیت در آنان به دو عامل موفقیت در زندگی و موفقیت در شغل مربوط است و بسیاری از زنان نگران آن هستند که موفقیت در تحصیل و شغل سبب به تعویق افتادن در ازدواج و تشکیل زندگی شود. این موقعیتی است که رگرسیون سلسله مراتبی و اثر تعدیلی اهمیت بسیار بیشتری از رگرسیون چندگانه دارد.
در مقاله غفاری و همکاران (2019) سه متغیر سرمایه اقتصادی، سرمایه نهادی و سرمایه اجتماعی به لحاظ مفهومی متفاوتاند، ولی به لحاظ مختصات روانسنجی چنین نیستند. ضرایب همبستگی نقش مهمی در نشاندادن تمایز متغیرها دارد. ازآنجاکه متغیرها همواره با متغیرهای دیگری رابطه دارند از طریقه همبستگی تفکیکی میتوان رابطه بین دو متغیر را مستقل از متغیر سوم تعیین کرد. ازآنجاکه حد 7/ 0 برای پایایی متغیر مطلوب است، میتوان حداکثر تا این حد دو متغیر را به لحاظ مفهومی متفاوت در نظر گرفت. در مقاله مزبور سرمایه نهادی و سرمایه اجتماعی به لحاظ روانسنجی یک متغیر است و تأکید متن مقاله آنها استفاده از زبان برای توجیه این مطلب است که آنها دو سازه مختلفاند.
اجازه دهید دادههای جدول 5 صفحه 40 مقاله آنها را مجدداً تحلیل کنیم. این جدول مربوط به ضرایب همبستگی سرمایه اقتصادی، سرمایه نهادی و سرمایه اجتماعی است. ضرایب پایایی به معنای ضریب همبستگی یک متغیر با خود ( ) و ضرایب روایی به معنی ضریب همبستگی یک متغیر با متغیر دیگر ( ) است. درواقع این دو ضریب مشابه دوقلوها و افراد عادی هستند. اگر همبستگی یک متغیر با متغیر دیگر از 7/ 0 بیشتر باشد در آن صورت این شک وجود دارد که آن دو متغیر درواقع یک متغیر باشند، که به دو گونه مختلف بیان شده است. میتوانیم از دادههای جدول 5 ضرایب همبستگی تفکیکی را از فرمول زیر محاسبه کنیم.
(معادله 1)
که ضریب همبستگی تفکیکی است یعنی همبستگی بین A و B را میسنجد هنگامیکه C از آن جدا شده باشد. با توجه به این فرمول ضریب همبستگی تفکیکی سرمایه اجتماعی و سرمایه نهادی برابر 96/ 0 و ضریب همبستگی سرمایه اقتصادی و اجتماعی برابر 62/ 0 به دست میآید که ضریب تعیین آنها برابر 92/ 0 و 38/ 0 است. میتوان آن را با نمودار زیر نشان داد:
نمودار (1)

بنابراین، سرمایه اجتماعی و سرمایه نهادی درواقع یک سازه هستند و با این حد از همپوشی بههیچعنوان نمیتوان آنها را دو سازه مجزا دانست. درواقع واریانس خطا 11/ 0 است که با محاسبه آن دو سرمایه کاملاً یکسان است. اشکال اساسی در آن است که این مقیاسها کاملاً دلخواه انتخاب شدهاند و اعتبار سازه آنها بررسی نشده است. مثلاً چرا سرمایه اجتماعی دارای دو زیر مقیاس مجزای سرمایه انسانی و اجتماعی است؟ آیا تحلیل عاملی اکتشافی این دو مقیاس را تأیید میکند؟ ثانیاً چگونه این عوامل تأیید شدهاند. سرمایه انسانی را نمیتوان برای سنجش سرمایه اجتماعی مورداستفاده قرار داد؛ بنابراین همه محاسبات بر پایه آن بر هالهای از شک و ابهام قرار میگیرد. در مورد مدل معادلات ساختاری در این مقاله باید به نکاتی که در همین مقاله در مورد این نوع معادلات آورده شده توجه کرد. درواقع ممکن است جهت فلشها تغییر کرده و مشارکت زنان در نیروی کار سرمایه اجتماعی را ایجاد کند و فقط از طریق روشهای همبستگی متقاطع تأخیری میتوان جهت فلشها را یافت. جدول 5 صفحه 40 مقاله مذکور را با توجه به ضرایب همبستگی تفکیکی از نو بازسازی کردهایم که در زیر مشاهده میشود.
جدول (1): رابطه متغیرها در پژوهش غفاری، هومنی و یوسفی، همبستگی معمولی و تفکیکی
| همبستگی متغیر |
همبستگی معمولی | همبستگی تفکیکی | ضریب تعیین | ||
| سرمایه اقتصادی | سرمایه نهادی | سرمایه اجتماعی | سرمایه اجتماعی | ||
| سرمایه اقتصادی | 1 | 839/ 0 | 900/ 0 | 62/ 0 | 38/ 0 |
| سرمایه نهادی | 792/ 0 | 1 | 887/ 0 | 96/ 0 | 92/ 0 |
| سرمایه اجتماعی | 900/ 0 | 887/ 0 | 1 | ــ | ــ |
متأسفانه در پژوهشهای رابطهای کمتر از رگرسیون لوجستیک استفاده میشود؛ درصورتیکه توانمندیهای آن بسیار است.
مثال مشهور آن را میتوان در پژوهش زیسمن و گانزاخ (2021) دید که در پژوهش خود نشان دادهاند که هوش در موفقیت تحصیلی دارای نسبت شانس 48 تا 90 برابر اراده و عزم است و هوش در شغل دارای نسبت شانس 13 نسبت به اراده و عزم است. درواقع آنجلاداک ورث توانسته بود در یک برنامه مشهور TED نشان دهد که عزم و اراده در پیشرفت تحصیلی بسیار مهمتر از هوش است. در اینجا دادهها به کمک آمدهاند و نشان دادهاند که این ادعا نادرست است. سخنرانی در 2013 ایراد شده بود و تا تابستان 2020، بیستویک میلیون نفر آن را مشاهده کرده بودند. ایدهای عمیقاً در جامعه رواج یافته بود اما یک پژوهش رگرسیون نشان داد که این ایده واقعیت ندارد.
2- نامگذاری دلبخواه عوامل در تحلیل عاملی
در مورد نامگذاری دلبخواه یکبار دیگر باید به «آلیس آن سوی آینه» باز گردیم (ترجمه محمدتقی بهرامیحران، 1995). در این جا هامپیتی دامپتی (که بهرامیحران او را «تپلی» ترجمه کرده است) میگوید آدم میتواند با انتخاب روز ناتولد، بهجای یک هدیه، سیصد و شصت و چهار هدیه در سال دریافت کند. بعد میگوید اینجا یک افتخار خوردهای! درواقع منظور او این است که یک شکست جانانه خوردی. منظور پذیرش یک هدیه بهجای سیصد و شصت و چهار هدیه است. آلیس اعتراض میکند که گونهای که او زبان را به کار میبرد معنی قابل انطباق نیست. ازاینجا هامپتی دامپتی با لحنی تا اندازهای سرزنشآمیز میگوید: وقتی من کلمهای را به کار میبرم به همان معنایی است که خودم برایش انتخاب کردهام. بهاینترتیب زبان معنی ارتباطی خود را از دست میدهد.
تحلیل عاملی اکتشافی را بسیاری از پژوهشگران مانند هامپتی دامپتی به کار میبرند. تحلیل عاملی اکتشافی تعدادی گویه را دستهبندی میکند که یک مفهوم مشترک آن گویهها را به هم متصل میکند. این مفهوم مشترک باید جامعومانع باشد. درواقع همه گویهها باید به مفهوم یک عامل باشند. گاهی چند گویه با یک نام متمایز میشوند که به همه آن گویهها اشاره ندارد. در این صورت تحلیل عاملی شکست خورده است. نباید تصور کرد که هر مخزنی از گویهها همواره به یک تحلیل عاملی موفق منجر میشود. تحلیل عاملی اکتشافی مستلزم کفایت حجم نمونه و بار عاملی بالاتر از 35/ 0 (ملاک گورساک) و مقدار ویژه بالاتر از واحد است. درعینحال تعیین استقلال عوامل (متعامد بودن آنها) یا وابسته بودن عوامل (اریب بودن آنها) باید با ملاکهای عینی تعیین شود. اما همه اینها بعد از آن است که نامگذاری عوامل به لحاظ مفهومی قابل توجیه باشد.
اگر گویههای عامل به لحاظ مفهومی با نام آن بیربط باشد تحلیل عاملی به شکست انجامیده است (مانند موقعی که در کتاب آلیس آن سوی آینه هامپتی دامپتی به جای شکست خوردی، میگوید افتخار خوردهای). این رویکرد به تحلیل عاملی در مقالات پژوهشی در زبان فارسی زیاد دیده میشود و دلیل آن نپذیرفتن شکست در تحلیل عاملی است که اتفاقاً زیاد رخ میدهد (در مقالات فارسی بهندرت اتفاق میافتد).
خطر این نوع تحلیل عاملهای نادرست نهفقط در پژوهش که در زبان هم هست و آن تحمیل واژگان نادرست بر مصادیق (گویهها) بهعنوان مفهوم است. داوران باید به گویهها در تحلیل عاملی اکتشافی نگاه کرده و تطابق آن با مفهوم عامل را داوری کنند. اجازه دهید برای ایضاح مطلب مثالی بزنیم. نصر، علامتساز، عریضی و نیلی (2002) هنگامیکه عوامل انتخاب رشته را دستهبندی میکردند دریافتند که گویههایی چون دوست دارم انتخاب رشته را در شهری دور از خانه انجام دهم (استقلال) و اعتبار دانشگاه برایم مهم است (اعتبار) و متناسب بودن رشته با استعداد من برایم اهمیت دارد (استعداد) و رشتهای برایم بیشتر ارزش دارد که سریعتر به بازار کار منجر شود (اقتصاد) روی یک عامل نشستهاند. پژوهشگران فوق تحلیل عاملی را شکست خورده اعلام کردند چون این مفاهیم متعدد با هم جمع شدنی نیستند. ممکن بود این گویهها را تحت عنوان میل به استقلال از خانواده طبقهبندی کنند و با اعلام موفقیت تحلیل عاملی، کار را ادامه دهند.
در دو مثال بعدی پژوهشگران روی عوامل نامگذاری دلبخواه انجام دادهاند. بیدل و همکاران (2015) متغیری به نام فردگرایی افراطی معرفی کردهاند. ولی معلوم نیست بر چه مبنای نظری این متغیر ساخته شده است؟ نقطه برش آن چیست؟ چگونه میتوان دامنه پیوستاری یک متغیر را کاهش داد و بخشی از آن را با نامهایی از قبیل افراطی مجزا کرد؟ اثر این کاهش دامنه بر همبستگی، یک رابطه غیرواقعی است. اما در پژوهش بعدی اثر نامگذاری دلبخواه بیشتر است.
روشنفکر و ذکایی (2006) گویههایی را که در تحلیل عاملی نتوانستهاند نامی برای آن بیابند، رفتارهای داوطلبانه خاصگرایانه نامیدهاند. دو عامل اول نیز هیچ تمایز مفهومی قابل استنادی ندارند و اگر تبدیل به دو عامل شدهاند به دلیل تصمیمی است که محققان گرفتهاند که عیناً مانند تصمیم هامپتی دامپیتی است: وقتی کلمهای را به کار میبرم به همان معنایی است که خودم برایش انتخاب کردهام. اید توجه داشت که تحلیل عاملی اکتشافی فرضیه ندارد و فقط در تحلیل عاملی تأییدی فرضیه وجود دارد. بااینحال آنها (ص 125) پژوهش خود را کمی و تجربی نامیدهاند که نادرست است. زیرا هرچند پژوهش آنها به دلیل استفاده از تحلیل عاملی و تحلیل تمیزی کمی است اما تجربی نیست. از طرف دیگر آن را مبتنی بر منطق فرضیه آزمایی از طریق تحلیل آماری دانستهاند درصورتیکه در رویکرد اکتشافی اصولاً فرضیه وجود ندارد و فرضیه مربوط به تحلیل عامل تأییدی است (عریضی،2007).
هنگامیکه آنها مخزن سؤالات خود را تحلیل عاملی کردند سه عامل را مجزا کردند که اولی را گرایشهای داوطلبانه شهروندی و دومی را گرایشهای داوطلبانه ارزشگرا نامیدهاند و سومی را که حاوی گویههایی از قبیل «کمک به اعضای خانواده برای پیشرفت» در زندگی است گرایشهای داوطلبانه خاصگرایانه نامیدند. مفهومسازی آنها مبتنی بر این است که گرایشهای داوطلبانه ارزشگرا مبنای فردی داشته ولی اهداف آنها معطوف به جمع است. آیا ارتقاء فرهنگ یا حفظ محیطزیست یا فعالیتهای فرهنگی و هنری را نمیتوان دارای مبنای فردگرایی دانست که تحت گرایشهای داوطلبانه شهروندی آمدهاند؟ یا این گرایشها جنبههای ارزشی ندارند که مجزا از گرایشهای داوطلبانه ارزشگرا قرار گرفتهاند؟ درواقع چون سؤالات روی عامل دیگری نشسته است آنها تحلیل عاملی را با نامگذاری دلبخواه نجات دادهاند. در تحلیل یافتهها هیچ جا بهاندازه تحلیل عاملی نامگذاری مهم نیست. در پسِ نام باید گویههایی قرار گیرند که به آن دلالت کنند. همه گویههای استفادهشده در گرایشهای داوطلبانه شهروندی ارزشی هستند.
تحلیل عاملی در بیشتر مواقع به شکست میانجامد. مثلاً سرسختی روانشناختی معمولاً در تحلیل عاملی به سه مؤلفه چالش، تعهد و کنترل تقسیم نمیشود. دلیل آن ساده است. درست است که گالیله تصور میکرد کتاب بزرگ طبیعت را با قوانین ریاضی نوشتهاند ولی جهان روانشناختی افراد با این سهولت با قوانین ریاضی نوشته نمیشود. در تحلیل عاملی هرگاه بتوان عاملها را نامگذاری کرد در آن صورت میتوان تحلیل عاملی را موفق دانست وگرنه نباید نتایج آن گزارش شود. معمولاً پژوهشگران پسازآن سعی میکنند بهصورت دلبخواه عوامل را نامگذاری کنند و تحلیلهای خود را ادامه دهند و پژوهشگران بعدی با کاربرد آن تحلیل عاملی به آن رسمیت میبخشند.
در پژوهش روشنفکر و ذکایی (2006) باید روی نمونه مجزایی دیگری تحلیل عاملی تأییدی انجام میشد و پسازآن که شاخصهای برازش به تأیید آن میپرداختند فرضیههای مقایسهای بین گروه داوطلبان و غیر داوطلبان با تحلیل تمیزی انجام میشد. در مواردی مانند پژوهش آنان، تحلیل تأییدی بیشتر موردنیاز است. چون تکرار نتایج روی دادههای مجزا شاید بتواند دلالت نادرست در مورد عوامل مجزا را کمرنگ کند. از طرف دیگر اطلاعات داده شده نشان از زاویه متعامد بین عوامل داوطلبانه شهروندی و ارزشگرا دارد. بهعبارتدیگر آنها مستقل از هم در نظر گرفته شدهاند. بهعنوان یک مثال از نمونهای که ضعیفتر از کار آنهاست به مقاله پاکنهاد و همکاران تحتتأثیر شبکههای اجتماعی مجازی بر سرمایه اجتماعی و قابلیتهای یادگیری سازمانی با نقش میانجی کنشهای یاریگرانه (2020) اشاره کنم. آنها نوشتهاند: «با توجه به اینکه پرسشنامه این تحقیق برگرفته از تحقیقات خارجی معتبر در این زمینه است لذا برای محاسبه روایی آن از تحلیل عاملی تأییدی استفاده شده است». همه این جملات درست است، ولی چیزی که آنها گزارش میکنند بارهای عاملی است که مربوط به تحلیل عاملی اکتشافی است؛ و وقتی به این نتیجه میرسند که همه بارهای عاملی از 3/ 0 بیشتر است به نادرستی نتیجه میگیرند که ساختار عاملی هر چهار پرسشنامه «قابلتأیید» است. درحالیکه منظور از قابلتأیید در تحلیل عاملی تأییدی آن است که شاخصهای برازش (تفصیلی و مطلق و باقیمانده و شاخص مجذور کای) به کار برده شود. بارهای عاملی که مربوط به تحلیل عاملی اکتشافی است نمیتواند ساختار عاملی را تأیید کند. بار دیگر هامپتی دامپتی در مقابل ما رخ مینماید. معنی کلمات آن چیزی است که من اراده میکنم.
تحلیل عاملی اکتشافی را بسیاری از پژوهشگران مانند هامپتی دامپتی به کار میبرند. تحلیل عاملی اکتشافی تعدادی گویه را دستهبندی میکند که یک مفهوم مشترک آن گویهها را به هم متصل میکند. این مفهوم مشترک باید جامعومانع باشد. درواقع همه گویهها باید به مفهوم یک عامل باشند. گاهی چند گویه با یک نام متمایز میشوند که به همه آن گویهها اشاره ندارد. در این صورت تحلیل عاملی شکست خورده است. نباید تصور کرد که هر مخزنی از گویهها همواره به یک تحلیل عاملی موفق منجر میشود. تحلیل عاملی اکتشافی مستلزم کفایت حجم نمونه و بار عاملی بالاتر از 35/ 0 (ملاک گورساک) و مقدار ویژه بالاتر از واحد است. درعینحال تعیین استقلال عوامل (متعامد بودن آنها) یا وابسته بودن عوامل (اریب بودن آنها) باید با ملاکهای عینی تعیین شود. اما همه اینها بعد از آن است که نامگذاری عوامل به لحاظ مفهومی قابل توجیه باشد.
اگر گویههای عامل به لحاظ مفهومی با نام آن بیربط باشد تحلیل عاملی به شکست انجامیده است (مانند موقعی که در کتاب آلیس آن سوی آینه هامپتی دامپتی به جای شکست خوردی، میگوید افتخار خوردهای). این رویکرد به تحلیل عاملی در مقالات پژوهشی در زبان فارسی زیاد دیده میشود و دلیل آن نپذیرفتن شکست در تحلیل عاملی است که اتفاقاً زیاد رخ میدهد (در مقالات فارسی بهندرت اتفاق میافتد).
خطر این نوع تحلیل عاملهای نادرست نهفقط در پژوهش که در زبان هم هست و آن تحمیل واژگان نادرست بر مصادیق (گویهها) بهعنوان مفهوم است. داوران باید به گویهها در تحلیل عاملی اکتشافی نگاه کرده و تطابق آن با مفهوم عامل را داوری کنند. اجازه دهید برای ایضاح مطلب مثالی بزنیم. نصر، علامتساز، عریضی و نیلی (2002) هنگامیکه عوامل انتخاب رشته را دستهبندی میکردند دریافتند که گویههایی چون دوست دارم انتخاب رشته را در شهری دور از خانه انجام دهم (استقلال) و اعتبار دانشگاه برایم مهم است (اعتبار) و متناسب بودن رشته با استعداد من برایم اهمیت دارد (استعداد) و رشتهای برایم بیشتر ارزش دارد که سریعتر به بازار کار منجر شود (اقتصاد) روی یک عامل نشستهاند. پژوهشگران فوق تحلیل عاملی را شکست خورده اعلام کردند چون این مفاهیم متعدد با هم جمع شدنی نیستند. ممکن بود این گویهها را تحت عنوان میل به استقلال از خانواده طبقهبندی کنند و با اعلام موفقیت تحلیل عاملی، کار را ادامه دهند.
در دو مثال بعدی پژوهشگران روی عوامل نامگذاری دلبخواه انجام دادهاند. بیدل و همکاران (2015) متغیری به نام فردگرایی افراطی معرفی کردهاند. ولی معلوم نیست بر چه مبنای نظری این متغیر ساخته شده است؟ نقطه برش آن چیست؟ چگونه میتوان دامنه پیوستاری یک متغیر را کاهش داد و بخشی از آن را با نامهایی از قبیل افراطی مجزا کرد؟ اثر این کاهش دامنه بر همبستگی، یک رابطه غیرواقعی است. اما در پژوهش بعدی اثر نامگذاری دلبخواه بیشتر است.
روشنفکر و ذکایی (2006) گویههایی را که در تحلیل عاملی نتوانستهاند نامی برای آن بیابند، رفتارهای داوطلبانه خاصگرایانه نامیدهاند. دو عامل اول نیز هیچ تمایز مفهومی قابل استنادی ندارند و اگر تبدیل به دو عامل شدهاند به دلیل تصمیمی است که محققان گرفتهاند که عیناً مانند تصمیم هامپتی دامپیتی است: وقتی کلمهای را به کار میبرم به همان معنایی است که خودم برایش انتخاب کردهام. اید توجه داشت که تحلیل عاملی اکتشافی فرضیه ندارد و فقط در تحلیل عاملی تأییدی فرضیه وجود دارد. بااینحال آنها (ص 125) پژوهش خود را کمی و تجربی نامیدهاند که نادرست است. زیرا هرچند پژوهش آنها به دلیل استفاده از تحلیل عاملی و تحلیل تمیزی کمی است اما تجربی نیست. از طرف دیگر آن را مبتنی بر منطق فرضیه آزمایی از طریق تحلیل آماری دانستهاند درصورتیکه در رویکرد اکتشافی اصولاً فرضیه وجود ندارد و فرضیه مربوط به تحلیل عامل تأییدی است (عریضی،2007).
هنگامیکه آنها مخزن سؤالات خود را تحلیل عاملی کردند سه عامل را مجزا کردند که اولی را گرایشهای داوطلبانه شهروندی و دومی را گرایشهای داوطلبانه ارزشگرا نامیدهاند و سومی را که حاوی گویههایی از قبیل «کمک به اعضای خانواده برای پیشرفت» در زندگی است گرایشهای داوطلبانه خاصگرایانه نامیدند. مفهومسازی آنها مبتنی بر این است که گرایشهای داوطلبانه ارزشگرا مبنای فردی داشته ولی اهداف آنها معطوف به جمع است. آیا ارتقاء فرهنگ یا حفظ محیطزیست یا فعالیتهای فرهنگی و هنری را نمیتوان دارای مبنای فردگرایی دانست که تحت گرایشهای داوطلبانه شهروندی آمدهاند؟ یا این گرایشها جنبههای ارزشی ندارند که مجزا از گرایشهای داوطلبانه ارزشگرا قرار گرفتهاند؟ درواقع چون سؤالات روی عامل دیگری نشسته است آنها تحلیل عاملی را با نامگذاری دلبخواه نجات دادهاند. در تحلیل یافتهها هیچ جا بهاندازه تحلیل عاملی نامگذاری مهم نیست. در پسِ نام باید گویههایی قرار گیرند که به آن دلالت کنند. همه گویههای استفادهشده در گرایشهای داوطلبانه شهروندی ارزشی هستند.
تحلیل عاملی در بیشتر مواقع به شکست میانجامد. مثلاً سرسختی روانشناختی معمولاً در تحلیل عاملی به سه مؤلفه چالش، تعهد و کنترل تقسیم نمیشود. دلیل آن ساده است. درست است که گالیله تصور میکرد کتاب بزرگ طبیعت را با قوانین ریاضی نوشتهاند ولی جهان روانشناختی افراد با این سهولت با قوانین ریاضی نوشته نمیشود. در تحلیل عاملی هرگاه بتوان عاملها را نامگذاری کرد در آن صورت میتوان تحلیل عاملی را موفق دانست وگرنه نباید نتایج آن گزارش شود. معمولاً پژوهشگران پسازآن سعی میکنند بهصورت دلبخواه عوامل را نامگذاری کنند و تحلیلهای خود را ادامه دهند و پژوهشگران بعدی با کاربرد آن تحلیل عاملی به آن رسمیت میبخشند.
در پژوهش روشنفکر و ذکایی (2006) باید روی نمونه مجزایی دیگری تحلیل عاملی تأییدی انجام میشد و پسازآن که شاخصهای برازش به تأیید آن میپرداختند فرضیههای مقایسهای بین گروه داوطلبان و غیر داوطلبان با تحلیل تمیزی انجام میشد. در مواردی مانند پژوهش آنان، تحلیل تأییدی بیشتر موردنیاز است. چون تکرار نتایج روی دادههای مجزا شاید بتواند دلالت نادرست در مورد عوامل مجزا را کمرنگ کند. از طرف دیگر اطلاعات داده شده نشان از زاویه متعامد بین عوامل داوطلبانه شهروندی و ارزشگرا دارد. بهعبارتدیگر آنها مستقل از هم در نظر گرفته شدهاند. بهعنوان یک مثال از نمونهای که ضعیفتر از کار آنهاست به مقاله پاکنهاد و همکاران تحتتأثیر شبکههای اجتماعی مجازی بر سرمایه اجتماعی و قابلیتهای یادگیری سازمانی با نقش میانجی کنشهای یاریگرانه (2020) اشاره کنم. آنها نوشتهاند: «با توجه به اینکه پرسشنامه این تحقیق برگرفته از تحقیقات خارجی معتبر در این زمینه است لذا برای محاسبه روایی آن از تحلیل عاملی تأییدی استفاده شده است». همه این جملات درست است، ولی چیزی که آنها گزارش میکنند بارهای عاملی است که مربوط به تحلیل عاملی اکتشافی است؛ و وقتی به این نتیجه میرسند که همه بارهای عاملی از 3/ 0 بیشتر است به نادرستی نتیجه میگیرند که ساختار عاملی هر چهار پرسشنامه «قابلتأیید» است. درحالیکه منظور از قابلتأیید در تحلیل عاملی تأییدی آن است که شاخصهای برازش (تفصیلی و مطلق و باقیمانده و شاخص مجذور کای) به کار برده شود. بارهای عاملی که مربوط به تحلیل عاملی اکتشافی است نمیتواند ساختار عاملی را تأیید کند. بار دیگر هامپتی دامپتی در مقابل ما رخ مینماید. معنی کلمات آن چیزی است که من اراده میکنم.
3- استفاده نادرست از شاخصهای برازش
در اینجا شاخص بکار میرود اما استفاده از آن غلط انجام میشود و این خطا بسیار شایعتر است. باید توجه داشت که اکثر خطاهایی که در پژوهشهای رابطهای وجود دارد مربوط به یک خطای منطقی است که در منطق به مغالطه وضع تالی مشهور است. رفع تالی جزء معروفترین صورتهای استدلالی معتبر است که میتوان آن را به شکل زیر نوشت.
مثلاً اگر باران ببارد، زمین تر میشود. اکنون زمین تر نیست. پس باران نباریده است. ولی مغالطه وضع تالی بهصورت زیر است.
نمونه این مغالطه آن است که با دیدن زمین تر نتیجه گرفته شود که حتماً باران آمده است. پیشفرضی که مبنای برازش مدل در تحلیل میانجی (واسطهای) است این است که هرگاه تحلیل میانجی درست باشد (P) آنگاه برازش دادهها وجود دارد (Q) اما اگر دادهها برازش داشته باشند (Q) لزوماً به معنی درستی تحلیل میانجی نیست. چنین استدلالی همان وضع تالی است که دیدیم بیاعتبار است. فقط اگر برازش وجود نداشته باشد (-Q) میتوان تحلیل میانجی را رد کرد. نهفقط در مورد تحلیل میانجی که در معادلات ساختاری نیز از شاخصهای برازش مطلوب برای تأیید فرضیههای پژوهشی استفاده شده است. شاخصهای برازش نمیتوانند در غیاب یک استدلال موجه درباره جهت بین متغیرها، آن را تأیید کنند. این استدلال موجه به طرح پژوهش مربوط است که البته در طرح رابطهای موجه نیست.
بهغلط تصور میشود که اگر شاخصهای برازش، مدلی را تأیید کنند، آن مدل کاملاً درست است. در این مورد دو اشکال وجود دارد: نخست اینکه اگر طرحهای پژوهش از نوع طولی یا آزمایشی نباشد شاخصهای برازش نهفقط آن مدل بلکه مدلهای همارز آن را نیز تأیید میکند (تارکا ، 2018). مثلاً در پژوهش اصغریکماء و همکاران (2021) میانجی به شکل مدل 1 مطرح شده است. مشکل این است که شاخصهای برازش نه فقط این مدل بلکه دو مدل همارز آن یعنی مدل همرس و مدل مخدوشکننده را نیز همزمان تأیید میکند (مدل 2 و 3).
این سه مدل همارز هستند؛ یعنی شاخصهای χ2 و درجه آزادی و CF و GF و RMSEA آنها یکی است. این شاخصها برخلاف دیدگاه نویسنده که تصور میکند مدل 1 را تأیید کرده است همزمان مدل 2 و 3 را نیز تأیید میکند و پژوهشگر نمیتواند با استفاده از شاخصهای برازش، تنها یکی از آنها را تأیید کند. هنگامی میتوان جهتگیری علی را در تأثیر شفقت به خود بر ادراک رفتارهای فداکارانه همسر تعیین کرد که یا از طرح پژوهش آزمایشی یا از طرح پژوهش طولی استفاده شده باشد، یا مبتنی بر نظریهای باشد که میتواند خود آن را در پژوهشی مستقل نگرهپردازی کرده باشد. اگر آن نظریه مبتنی بر یافتههای رابطهای باشد هرچند ضعیف اما قابل استنباط است اما نمیتوان با استدلالهای کلامی از نوع هامپتی دامپتیوار نتیجهگیری کرد. متأسفانه گاهی از این استدلالهای کلامی فراتر رفته و نتیجه تحقیقهای دیگر را برای توجیه مدل خود به کار میبرند.
در اینجا مسئله سوگیری (مثل سوگیری پیشینه خوب و سوگیری نتایج مثبت، نگاه کنید به عریضی و فراهانی، 2008) وجود دارد یعنی تنها تحقیقاتی را ذکر کنند که در جهت مدل میتوان آن را بکار گرفت که اکثراً نابسنده است؛ اما گاهی (مثل همین مقاله) نتایجی را به تحقیق نسبت میدهند که در آن وجود ندارد. در بخش دیگر به آن بازخواهم گشت. در آن صورت نیز بین مدل 1 و مدل 2 یعنی مدل میانجی و همرس نمیتوان تمایز قائل شد مگر اینکه با طرح طولی یا آزمایشی نشان داده شود که ادراک رفتارهای فداکارانه همسر بر خودمهارگری تأثیر دارد.
به لحاظ مفهومی هر سه مدل قابل توجیه است. مثلاً اگر فرد خودمهارگری بالا داشته باشد آیا در طول زمان رفتارهای فداکارانه همسر را به دنبال نخواهد داشت؟ درواقع رابطه متغیرها در هر دو جهت امکانپذیر است. پژوهشهایی که در آنها میزان و درجه آزادی و CF و GF و RMSEA از یکدیگر کم میشوند و بر مبنای این تفاضل یکی بر دیگری ترجیح داده میشود در اساس همارز نبوده و این تفاضل صفر نمیشود.
در آنجا میتوان از ترجیح یک مدل بر مدل دیگر سخن گفت. آن نوع مدلها، مدلهای رقیب نامیده میشود. درعینحال امکان بیشتری به لحاظ مفهومی هست که خود مهارگری متغیر تعدیلی بین ادراک رفتارهای فداکارانه همسر و شفقت به خود باشد. درواقع افراد با خودمهارگری بالا میتوانند همزمان با شفقت به خود، رفتارهای فداکارانه همسر را ارتقا دهند و رابطه بین آنها از این رابطه در افراد با خود مهارگری پایینتر است. دلیل آن این است که افراد با خودمهارگری بالاتر بوده و بنابراین کمتر از گرایش به خود خارج میشوند. بهتبع آن در ادراک رفتارهای فداکارانه همسر ضعیفتر خواهند بود (یادداشت 1). بهعبارتدیگر در ارزشهای خودتقویتی (شوارتز 2003) و خودمرکزی (دامبران و رایکا ، 2012) نمره پایینی دریافت میکنند.
جالب آن است که اصغریکماء و همکاران (2021) در پژوهش خود از تحلیل مسیر استفاده کردهاند که در آن تحلیل تأییدی و شاخصهای برازش بیمعنی است. درواقع فقط در مدل معادلات ساختاری که از دو بخش سنجشی و ساختاری تشکیل شده است تحلیل تأییدی قابل انجام است. در تحلیل مسیر این کار بیمعناست. اما اگر این پژوهشگران از مدل معادلات ساختاری استفاده کرده بودند مسئله نیز تفاوتی نمیکرد و همچنان امکان نتیجهگیری علی وجود نداشت. فقط در صورت استفاده از طرحهای آزمایشی یا طولی یا نظریهای استوار به دادههای پژوهشی امکان چنین نتیجهگیری وجود داشت. دلیل آن این است که مدل معادلات ساختاری و مدل تحلیل مسیر چون صرفاً رابطه را بیان میکنند نسبت به جهتگیری متقارن هستند و هر شکلی از نوشتن معادله این تقارن را حفظ میکند. در بخش دیگر مجدداً به این مقاله بازخواهیم گشت تا نشان دهیم ارجاع به پیشینه تا چه حد در آن ضعیف است.
در پژوهش دیگر گودرزی و همکاران (2021) جملهای که در اکثر پژوهشهای شبیه به آن وجود دارد، نوشته شده است:
اهمیت این مقاله در آن است که تابهحال در پژوهش کمتر به اثر سبک روابط خانوادگی (مانند نحوه تعارض بروز هیجانی و انسجام خانوادگی) در مورد رفتارهای آسیبرسان با نقش عوامل منفی و دشواری در تنظیم هیجانی پرداخته شده است.
موضوعی که نویسنده سطور فوق باید بداند اینکه نمیتواند با شاخصهای برازش این مدل را تأیید کرد. دلیل اینکه در این همه پژوهشهای انجامشده به این روابط اشارهای نشده است به دلیل نادرستی این شیوه تحلیل است که نمیتواند این جهات علی را با جمعآوری دادههای میدانی و کاربست آن در مدل معادلات ساختاری مورد تأیید قرار داد. درواقع انبوهی از این نوع مقالهها که رابطه دومتغیره از طریق یک میانجی را بررسی میکند در ادبیات پژوهشی وجود دارد که صرفاً برای توجیه آن، دوبهدو، به رابطههای متغیرهای دخیل در آن از طریق زبان پرداختهاند. توجیهات معمولاً با کمی چرخش در زبان در جهت عکس هم امکانپذیر است. از رابطه متقارن دوطرفه نمیتوان به روابط سه متغیره نامتقارن رسید زیرا معادله ساختاری حافظ تقارنی است که بین متغیرها وجود دارد.
تحلیل رگرسیون چندگانه را که سادهترین شکل پیشبینی متغیر y از n متغیر پیشبینی کننده است میتوان یک ماشین نادرست از مدل ذهنی پژوهشگرانی دانست که بهصورت دلخواه این متغیرها را برای تعریف معادلهای ساده از رگرسیون پیشنهاد میکند. 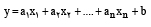
متغیرهای میتوانند هر متغیری باشند که از طریق پیشینه با y مرتبط شدهاند. ممکن است متغیرهای از طریق یک متغیر با y همبستگی خیالی پدید آورند. معمولاً از طریق این متغیرهای سوم همواره رابطهای قابلتصور است. بدترین وضعیت برای پژوهشهای رابطهای آن است که هیچ رابطهای از قبل اندیشیده شده و مبتنی بر پیشینه نظری نباشد. همچنین این متغیرها نباید متغیرهایی باشند که با وجود تناقض با یکدیگر همزمان در فرد وجود داشته باشند؛ بنابراین تعریف آن در وجود یک فرد موهومی باشد. مثلاً اگر فردی دارای دلبستگی ایمن باشد، نمیتواند همزمان سبک دلبستگی ناایمن هم داشته باشد. بهعبارتدیگر، نقطه برشی وجود دارد که اگر نمره فرد زیر آن نقطه باشد، سبک دلبستگی ناایمن دارد و اگر نمرهاش بالای آن نقطه باشد، سبک دلبستگی او را ایمن باید محسوب کرد. این متفاوت از ویژگیهای شخصیتی از قبیل برونگرایی یا درونگرایی است که افراد روی یک پیوستار قرار میگیرند و میتوانند هراندازهای در این پیوستار کسب کنند.
باید توجه داشت که رگرسیون چندگانه دارای فرضیه نیست زیرا باید ترتیب متغیرها و اصولاً انتخاب آنها توسط پیشینه معلوم شود؛ درحالیکه پژوهشگر از قبل نمیتواند چنین ترتیبی را مقرر کند بلکه این ماشین است که ترتیب را بر مبنای WDR و YPB مشخص میکند. بهاینترتیب اندیشیدن به سهولت فشردن یک دکمه تبدیل میشود! اگر متغیرها بر اساس پیشینه یا نظریه در مدل آورده شده باشند، از رگرسیون توانمندتری باید استفاده کرد که رگرسیون سلسهمراتبی نامیده میشود. رگرسیونهای چندگانه و سلسله مراتبی به ترتیب مثالهایی از تحلیل اکتشافی و تحلیل تأییدی است. تفاوت عمده آنها این است که تحلیلهای اکتشافی دارای فرضیه نبوده و بنابراین نمیتوان آنها را به جز یک جستجوی تیری در تاریکی چیز دیگری دانست. اصطلاحی که گال، بورگ و گال (1996) برای این نوع جستجو انتخاب کردهاند.
در مدل ذهنی نادرستی که پژوهشهای زیادی را در ایران تولید کرده و معمولاً در عنوان این پژوهشها رابطه ساده و چندگانه دیده میشود، فرضیه اصلی این است که ترکیبی از متغیرهای x2 متغیر y را پیشبینی میکند. من این جملهها را فرضیهنما مینامم زیرا هیچگاه این فرضیهها باطل نمیشوند و همواره تأیید میشوند؛ تأییدی که البته واقعی نیست زیرا یک فرضیه پژوهشی بنا بر ملاکهای فلسفه علم باید ابطالپذیر باشد، درصورتیکه این جملهها ابطالپذیر نبوده و شبیه گزارههای فلسفی هستند. کامپیوتر از دو تابع حداقل مجذورات و بیشینه احتمالی برای ترتیب این متغیرها سود میجوید و ظاهراً برای این مدل ذهنی پاسخی جادویی فراهم میآورد: فرضیههای که همواره تأیید میشوند. باید توجه داشت که رگرسیونهای چندگانه نوعی جستجوی خوابگردانه است. درجایی که هیچ رابطه مبتنی بر فرضیه نمیتوان بین متغیرها ترسیم کرد و بسته به ماهیت پژوهش میتوان از هر یک از شکلهای پیشرو ، پسرو یا گامبهگام استفاده کرد. بعد از آن میتوان این جستجوی خوابگردانه را با طرحهای پژوهشی قوی از قبیل طرحهای طولی یا آزمایشی دنبال کرد و بهصورت مستقل نمیتوان آن را پژوهش نامید. بعداً و در آن مرحله میتوان فرضیه برای پژوهش نوشت.
خوشبختانه استفاده از آنها در مقالههای رفاه اجتماعی فقط محدود به یک مقاله است. نامنی و همکاران (2016) تعهد زناشویی را بر اساس سبکهای عشقورزی پیشبینی کردهاند که این سبکهای عشقورزی شامل رمانتیک، جنونآمیز و وفادارانه است که افراد در زندگی زناشویی یکی از این شکلهای عشقورزی را دارند که نمیتوان بین آنها رابطه نموی برقرار کرد و حتی اگر چنین باشد نمیتوان برای آن فرضیهای ساخت. اینکه عشق جنونآمیز به عشق رومانتیک چیزی میافزاید درواقع بیمعناست. این دو عشق در وجود فرد واحدی نیستند که دومی بر اولی افزوده شود درحالیکه معادله رگرسیون مبتنی بر این افزونگی است. در مقاله دیگری هم (نامنی و قربانی، 2018) این روش این بار در مدل معادلات ساختاری دنبال شده است.
در مقاله، خود آنها راجع به Red CV ادعایی کردند که درست نیست و به معنی باوری است که بسیاری از محققان علوم انسانی نسبت به تواناییهای مدل معادلات ساختاری دارند، حتی گاهی آن را مدل علی هم نامیدهاند. در ص 166 ادعا شده است:
آزمون کیفیت مدل ساختاری را بیان میکند به این معنی که ... آیا متغیرهای مناسبی در قالب مدل ساختاری قرارگرفتهاند یا خیر. آیا فرضیات پژوهشی مناسب انتخاب شده یا خیر (منظور نویسنده آزمون استون گایزر است). با توجه به محدودیت فضا در مدل PLS دو شاخص در بخش ارزیابی، اشتراک com و افزونگی Red است که به ترتیب مقادیر آن مجذور همبستگی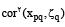 و میانگین واریانس مجموعه متغیرهای آشکار است.
و میانگین واریانس مجموعه متغیرهای آشکار است.
در آزمون استون گایزر که در آن بخشی از ماتریس دادهها به کمک روش جک نایف برای برآورد پارامترها حذف شده و از طریق پارامترهای برآورده شده بخش حذفشده برآورد میشود (شبیه روش اعتباریابی متقاطع یا روشهای مشابه دیگر در باز نمونهگیری) در این حالت اگر مقدار Red CVv (که هم نامیده میشود) منفی باشد برآورد بلوکهای ارزیابی شده ضعیف است. انتخاب متغیرها و درستی فرضیهها کاملاً در فضای مفهومی پژوهش ایجاد شده و هیچ ربطی به محاسبات فوق ندارد. کتاب هنسلر و همکاران (2009) که در منابع نامنی و قربانی (2018) به آن اشاره نشده، اما به آن ارجاع داده شده است، درواقع نویسندگان رانیارتز، هنیلین و هینسلر (2009) است که کاربردهای PLS در بازاریابی شرح داده شده است و مقالات بسیار تخصصیتر را میتوان (حتی در زبان فارسی) راجع به PLS یافت.
جان سرل، فیلسوف مشهور، استعارهای ساخته است که مرد چینی نام دارد و دستورالعملهایی را به فردی که زبان چینی نمیداند ارائه میدهد و آن فرد باید بدون دانستن زبان چینی و فقط در سطح صورت از آن دستورالعملها نتیجهگیری کند، درحالیکه آن فرد برای فهم درست دستورالعملها نخست باید زبان چینی را بفهمد. موقعیت کاربرد نرمافزارها بهخصوص مدل معادلات ساختاری بسیار شبیه دستورالعملهای مرد چینی است: پژوهشگرانی که آن را به کار میبرند، نخست باید منطق آن را بدانند.
برای اینکه ضعف پیشینه درنتیجهگیری میانجی در تحقیق را نشان دهم به یک پژوهش دیگر اشاره میکنم که هم در جهان انگلیسیزبان (دامبران و رایکار 2011) و هم در جهان فرانسه زبان (دامبران، 2011 و دامبران و رایکار 2012) بهخوبی پیشینه آن شناخته شده است و بنابراین نظریهای استوار در مورد آن وجود دارد و بسیار متفاوت از استدلالهای مبتنی بر چند برداشت سطحی است. این پژوهش در مورد نقش میانجی پایداری هیجانی (با N در NEO) بین دو متغیر فداکاری (ناخودی) و شادی اصیل و مستمر است. نظریه آنها مبتنی بر این فرضیه است که شادی در افراد خود مرکز بین ناپایدار است. درحالیکه شادی در افراد فداکار (ناخود) از پایداری هیجانی برخوردار است. او برای انجام تحلیل میانجی نخست با تحلیل عاملی اکتشافی و تأییدی مجزابودن دو سازه ناخودی (فداکاری) و خودمرکزبینی را نشان میدهد و سپس همبستههای آنها (شادی اصیل و خودمتعالی برای ناخودی و شادی ناپایدار برای خودمرکزبینی) را بر اساس نظریههای متعدد در طول ده سال گذشته و دادههای تجربی مطالعه اول خود، وارد مدل تحلیل میانجی میکند. اصغری و همکاران که به حیطه خاص سازه ناخودی در رفتار همسر پرداختهاند به نظریهپرداز آن و مجموعه وسیع کارهای او هیچ اشارهای نمیکنند. آنها رابطهای را بر مبنای پیشینه در مقاله خود آن هم فقط در یک سطر به نقل از استنفنسون و همکاران (2014) به نقل از عباس و رستمی 2020 میآورند که نقش ضربهگیر فداکاری همسر است.
این مدل با توجه به پیشینه و درک عادی غلط است و به نظر میرسد که خود مهارگری نقش تعدیلگر دارد، اما در این مطالعه بهعنوان متغیر میانجی در نظر گرفته شده است. اینکه متغیرهای ضربهگیر همواره متغیر تعدیلگر در نظر گرفته میشوند نیاز به بحث مفصلی دارد و مقاله مستقلی میطلبد. اما سؤال این است که چرا پژوهشگران ترجیح میدهند به آن نقش میانجی بدهند. یک دلیل ساده این است که ارائه آن با مدل معادلات ساختاری راحتتر است. در ایران فقط یک مقاله در مورد نقش تعدیلگر با استفاده از مدل معادلات ساختاری گزارش شده که در بخش سیزدهم همین مقاله به آن اشاره شده است.
مورد دوم مقاله ایرانی و همکاران (2018) است که در آن نیز تحلیل میانجی به جای تحلیل تعدیلی بکار رفته است. خطاهای مقاله از همان آغاز و در عنوان مشخص است مسکن مهر و مسکن اجتماعی دو پدیده کاملاً مختلف و با اهداف متفاوت هستند. سؤال پژوهش این است که سیاستگذاری و اجرای مسکن اجتماعی با چه آسیبهایی روبروست و پیامدهای آن در بازتولید نابرابری طبقاتی و گرایش به انحرافات اجتماعی در محیط مسکونی واقع در مسکن مهر تبریز سهند چگونه است؟ نویسنده از همان آغاز در ذهن خویش هیچ اشارهای به مسکن مهر نکرده و به جای آن به مطالعات مسکن اجتماعی در پیشینه نظری اشاره کرده و در بخش پیشینه تجربی غیر از اشاره به نام پژوهشها (داخلی و خارجی) هیچ چهارچوب پنداشتی در معرض بحث قرار نگرفته است و ناگهان، بدون هیچ مبنای منطقی مدل زیر پیشنهاد میشود (ص 154) این مدل یکی از سه مدل همارز (همرس ، مخدوشگر و میانجی ) است یعنی مدل مخدوشگر است که بهوضوح نادرست است.
در همه جای جهان افراد ثروتمند در وضعیتهای فضایی خاصی ساکن میشوند که بر تمایز آنها از دیگران تأکید میکند و افراد فقیر نیز در وضعیتهای محلههای فقیرنشین سکنا میگزیند. این نابرابری اجتماعی است که سکونت در وضعیت فضایی را ایجاب میکند و نه اینکه سکونت در آن فضا مقدم بر نابرابری اجتماعی است. از زمان مارکس این ایده تثبیت شده است که نابرابری اجتماعی زیربنا و علت و منشأ روبناهایی از قبیل سکونت در وضعیت فضایی و گرایش به آسیبهای اجتماعی است. نویسندگان به نادرست یک مدل میانجی را به شکل مدل مخدوشگر ترسیم کردهاند. هرچند شاخصهای برازش هیچ تفاوتی با یکدیگر ندارد و به همین دلیل آنها را مدلهای همارز میگویند. تصور نویسندگان آن است که مدلی را تأیید کردهاند که ترسیم کردهاند ولی مدل درست، مدل همارز آن یعنی مدل میانجی است.
نویسندگان در مدل فوق، بدون هیچ دلیلی وضعیت سکونت در مسکن مهر را بهعنوان وضعیتی تلقی کردهاند که محرومیت اجتماعی را برای ساکنانش به لحاظ طرد و تفکیک قشری و بازتولید نابرابری ایجاد کرده است (ص 151). این جمله علیرغم طنین لوفوری که دارد، کاملاً از اندیشههای او خالی است. درواقع جهت فلش از نابرابری اجتماعی سکونت در وضعیت فضایی مسکن مهر با منطق هماهنگتر است. مثلاً فقر که عامل شناختهشدهای برای افزایش گرایش به آسیبهای اجتماعی است، در زاغهها و حاشیهها بهتر محل بروز دارد یا سکونت در وضعیت فضایی مسکن مهر؟ برای پاسخ به این سؤال بهتر است گروه پایه مقایسه (حاشیهنشینها) وجود داشته باشد و بدون آن هیچ نتیجهگیری درست نیست.
یکی از خطاهای پایهای این تحقیق آن است که باید از مدلسازی خطی سلسله مراتبی (HLM) استفاده میشد. در آینده در مجله رفاه اجتماعی مقالهای خواهم نوشت و در آن روش تحلیل این دادهها را نشان خواهم داد.
نویسندگان به جای گروه پایه، سکونت را بهصورت یک متغیر پیوسته درآوردهاند و بنابراین تحلیل آنها یک موضوع بسیار ساده و از پیشدانستهای است: فقر سبب میشود که انحراف از هنجارهای اجتماعی صورت پذیرد.
در این حالت محل سکونت بهصورت متغیر تعدیلگر درآمده و رابطه طبیعی نابرابری اجتماعی گرایش به آسیبهای اجتماعی تحت تأثیر آن قرار میگیرد. برخلاف تصور نویسندگان مقاله، شاخص افزونگی (Redcv) Structural model quali index نمیتواند تعیین کند که آیا متغیرهای مناسبی در قالب مدل ساختاری قرار گرفتهاند یا خیر. درواقع شاخصهای تأیید که مدل را تأیید میکنند هر نوع تغییر جهت فلشها را هم تأیید میکنند و مجموعه این بحث در ادبیات آماری به مدلهای همارز شهرت دارد. (ازجمله مثل مدل میانجی با متغیر مخدوشکننده همارز است که در بخش چهارم به آن پرداخته شد). اگر این تحلیل میانجی باشد، چهارچوب نظری درستی ندارد، زیرا سکونت در مسکن مهر تحت تأثیر نابرابری اجتماعی است که به نظر نویسنده مقاله حاضر و خلاف نظر نویسندگان مقاله قابلقبول است. ولی در مورد متغیر سوم یعنی گرایش به آسیبهای اجتماعی، درست به نظر نمیرسد که گرایش به آسیب اجتماعی از سکونت در مسکن مهر ناشی شود. این ادعای بزرگی است که خلاف جهت بین دو متغیر دیگر نیاز به تغییر طرح پژوهش دارد. یعنی در یک مطالعه طولی باید بررسی شود که آیا سکونت در وضعیت فضایی مسکن مهر است که گرایش به آسیبهای اجتماعی را میسازد یا برعکس این گرایش به آسیبهای اجتماعی است که سکونت در وضعیت فضایی مسکن مهر را پدید میآورد و هیچ پیشینهای در این زمینه وجود ندارد. هرچند این یک متغیر طبقهای است. اما پژوهشگران به دلیل تمایل به کاربرد PLS از آن یک متغیر پیوسته ساختهاند (ص 156). پژوهشگران در توجیه این کار خود امکان سنجش متغیرها در سطح فاصلهای و درنتیجه امکان بهکارگیری آزمونهای پیشرفته آماری را میآورند... درواقع یا پیوسته کردن سکونت، سکونت در وضعیت مسکن مهر به معنی طبقه اجتماعی پایین (فقیر) خواهد بود. بنابراین فرضیه ساخته شده توسط پژوهشگران امری بدیهی است یعنی فقر، آسیب اجتماعی و نابرابری اجتماعی ایجاد میکند. اگر سکونت در وضعیت مسکن مهر با سطح پایه پایینتر خود مقایسه میشد (مثلاً زندگی در زاغه) در آن صورت نتایج کاملاً متفاوت بود. کاربرد آزمون t (سوبل) نادرست بوده و باید همانطور که در همه مقالات تحلیل میانجی نوشته شده از توزیعهای تجربی (بوت استراپ یا جک نایف) استفاده شود. مطالب بحث و نتیجهگیری حاوی خطاهای پرشماری است. فقط به یکی از آنها اشاره میکنم نویسندگان مدعی شدهاند که نابرابری امنیت اجتماعی بر گرایش به آسیبهای اجتماعی بیش از غیر ساکنان مؤثر بوده است. آزمون آن فقط از طریق تحلیلهای موسوم به میانجی تعدیلی (عریضی،1387) امکانپذیر است که در پژوهش حاضر این تحلیل انجام نشده است؛ الگویی که من به جای الگوی فوق منطقی میدانم. ادعاهایی که در مورد PLS شده، غیرواقعی است. ازجمله این ادعا که اجرای همزمان مدلسازی اکتشافی و تأییدی از ویژگیهای Smart PLS است. این ادعاها درباره نرمافزارها و ماشین را در بخش چهارم همین مقاله به تفضیل موردبحث قرار دادم. بسیاری از نرمافزارها میتوانند مدلسازی اکتشافی و تأییدی را بهطور همزمان اجرا کنند. این پژوهشگر است که تشخیص میدهد کدام دادهها باید در معرض تحلیل اکتشافی و کدام دادهها در معرض تحلیل تأییدی قرار گیرند. مرحله اول در مثلاً تحلیل عاملی، تحلیل عاملی اکتشافی EFA و در مرحله دوم و روی دادههای مجزا تحلیل عاملی تأییدی CFA انجام میگیرد. برای مطالعه تحلیل تأییدی و اکتشافی و تفاوت آن دو با یکدیگر و اینکه دادههای این دو نوع تحلیل متفاوتند یک مقاله خوب عریضی (2007) به فارسی وجود دارد. درواقع دو خانواده از روشها در مدلسازی معادلات ساختاری وجود دارد که یک روش با مبنای عاملی (رویکرد تأییدی) و دیگری با مبنای مؤلفهای (رویکرد اکتشافی) است. که در اولی متغیرهای مکنون معادل عامل مشترک و در دومی مجموع موزون متغیرهای آشکار است.
این الگوست که با عقل سلیم و پیشینه پژوهشها بیشتر هماهنگ است.
این تحلیل، یک تحلیل تعدیلی است که در آن سکونت در مسکن مهر بر رابطه تأثیر میگذارد (و نه آن که مانند تحلیل میانجی آن را ایجاد کند). ممکن است نویسندگان تصور کنند مدل آنها تأیید شده است و امکان ندارد که با دادههای آنها این امر میسر باشد.
گاهی پژوهشگران مدلهای میانجی و تعدیلی را خلط کردهاند، مثلاً: در پژوهش محمود علیلو و همکاران (2014)، هم عقل سلیم و هم پیشینه نظری، این مدل را تأیید میکند.
آنها اما فقط و فقط به دلیل ترجمه غلط در پیشینه نظری و شباهت صوری دو واژه Moderating و Mediating تصور کردهاند که الکسی تیمیا نقش میانجی دارد. آنها به نقل از گرانر و همکاران (2011) به این نقش میانجی اشاره کردهاند و دادهها را به دلیل ترجمه نادرست با تحلیل میانجی تأیید کردهاند. درحالیکه در ابتدا باید تحلیلهای تعدیلی صورت گیرد تا تحلیل میانجی انجام شود. باز هم تأیید مدل با شاخصهای برازش به معنی درستی آن نیست (به مورد سوم در همین مقاله نگاه کنید). گاهی افراد مدل نادرستی را برای پژوهش خود استفاده کردند. مثلاً پاکنهاد و همکاران (2020) در صفحات 60 و 67 متغیر کنش یاریگرانه را متغیر تعدیلی بین شبکههای اجتماعی مجازی و قابلیت یادگیری سازمانی معرفی کرده است؛ درصورتیکه هم آمارهها و هم نمودارها در مقاله خود او این متغیر میانجی است. جالب است که بدون توجیه مدل او از شاخصهای تأییدی برای تأیید مدل استفاده کرده است. قبلاً او باید برای تأیید ابراز خود در تحلیل عاملی از این شاخصها استفاده میکرد. یعنی جایی که نباید از آنها استفاده کند آنها را به کار برده است (در تأیید مدل نظری) و جایی که باید از آنها استفاده میکرد آنها را به کار نبرده است (در تأیید ساختار عاملی ابزارها).
استفاده از آزمون سوبل هم نادرست است که جای دیگر به آن اشاره کردهام. نیکوگفتار (2014) فکر میکند متغیر میانجی و تعدیلی اصولاً یکی است (صفحه 123). او آنها را به صورتی کامل مترادف به کار میبرد. ناآشنایی با تعاریف متغیرها در مجله رفاه اجتماعی زیاد به چشم میخورد که بارزترین آن بین متغیر میانجی و تعدیلی است.
در کل سه متغیر میانجی در محله رفاه اجتماعی بررسی شده است. علاوه بر مقاله فوق دو مقاله پاکنهاد و همکاران(2020) و گودرزی و همکاران (2021) نیز وجود دارد. در هیچ یک از این دو مقاله نقش میانجی در پیشینه توجیه نشده است. در مقاله اول اصولاً پژوهشگران گاهی متغیر کنش یاریگرانه را میانجی (در عنوان) و گاهی تعدیلی (مثلاً صفحه 60) نامیدهاند که نشان میدهد پژوهشگران تفاوتی بین آنها قائل نیستند. درواقع هیچکدام از دو پژوهش ادریسی و رحمان خلیلی (2012) و ابوالحسنی رنجبر (2012) که برای توجیه تأثیر شبکههای مجازی بر کنشهای یاریگرانه آمدهاند ربطی به آن ندارد. به نظر میرسد که نقش تعدیلی بر نقش میانجی برای کنشهای یادگیرانه منطقیتر به نظر میرسد و هیچ توجیهی برای این مدل وجود ندارد و کاملاً غلط است. جدول (1) که تحت عنوان تحلیل عاملی تأییدی آمده است بارهای عاملی آمده که نادرست است و باید شاخصهای برازش گزارش میشد. در مقاله دوم نیکوگفتار (2014) مجدداً تحلیل میانجی و تعدیلی را یکی گرفته است (ص 123) که خطا است.
6- استدلال به شیوه هامپتی دامپتی
در مورد تحلیل تعدیلی و میانجی، گزی و محمدیآریا (2015) به شیوهای بینظم به رابطه سرمایه اجتماعی و فرهنگ سازمانی پرداختهاند. بحث آنها در موارد پیشینه زاید و بیربط است. در جدول (1) که خلاصه پژوهشهاست فقط سه پژوهش راب و زامسکی (2001)، بوگلزدیک (2003) و طاهره فیضی (1387) به موضوع ظاهراً مرتبط است و بقیه کاملاً بیارتباط است. به نظر میرسد پژوهشگران برای مستند ساختن مطالب خود مطالبی را به پژوهشهای دیگران نسبت میدهند تا زبان خصوصی خود را مستدل کنند. مثلاً پژوهش راب و زمسکی (2000) را چنین شرح میدهند که مطلوبیت همکاری به میزان همکاری دیگران در گذشته و شدت انگیزش وابسته است امری که واضح است و چندان ربطی به فرهنگ سازمانی ندارد اما چگونه به سرمایه اجتماعی موضوع پیوند میخورد؟ همکاری نیروی کار که تا اینجا سعی میشود به آن نقش فرهنگ سازمانی (مشارکتی) داده شود (صفحه 142) در سطر بعد به معنای سرمایه اجتماعی است. نویسندگان ادامه میدهند همکاری نیروی کار (سرمایه اجتماعی) فرآیند پویایی را دنبال میکند که در آن شدت انگیزش بهعنوان متغیر کنترلکننده عمل میکند. لابد اگر رابطه این متغیرها با انرژی رابطهای مطرح میشد نویسندگان در جمله بعد مینوشتند میزان همکاری مطلوبیت (انرژی رابطهای) فرایندی اثربخش است که تابع سازوکارهای کنترلی ازجمله شدت انگیزه است.
در آمار ارائهشده پژوهشگران همچنان فرضیههای ساختگی را با آماری نادرست دنبال میکنند، آنها مدعیاند که تحلیل دادهها متناسب با سطح سنجش متغیرها صورت گرفته است. امری که حرف آن را میزنند اما اجرا نکردهاند زیرا از تحلیل چند سطحی که توصیه یکی از منابع آنهاست استفاده نکردهاند. آنها در جدول 7 (صفحه 155) مجموعهای از رابطههای دو متغیری بین دانشگاه، جنسیت، وضعیت تأهل، محل سکونت، وضعیت بومی و وضعیت استخدامی را تحت عنوان متغیرهای تعدیلی آوردهاند اما در هر مورد دوگانهای (مثلاً مرد و زن) ساخته و رابطههای مستقل آن را با این متغیرها گزارش دادهاند. مثلاً در مورد جنسیت ضرایب همبستگی 368/ 0 (مرد) و 575/ 0 (زن) را به دست آوردهاند؛ اما معلوم نیست که اینها چه تفاوتی دارند. اگر به z فیشر تبدیل و ضرایب همبستگی مقایسه میشوند باز هم به معنی نقش تعدیلی نیست. در مورد اثر غیرمستقیم (میانجی) هم نتایج رها شده و معنیداری آن با بوت استراپ بررسی نشده است (صفحه 157).
7- عدم توجه به محدودیت دامنه و استنتاجِ نبودِ رابطه بین متغیرهایی که بهوضوح دارای ارتباط هستند.
در مقاله دیگری که حقیقیان و جعفری (2013) در مورد سرمایه اجتماعی و بهداشت روانی در میان حاشیهنشینان نوشتهاند نکته عجیبی که وجود دارد این است که رابطه پایگاه اجتماعی ـ اقتصادی تنها 02/ 0 بهداشت روانی را تبیین میکند و 98% آن مربوط به عوامل دیگر است. این با پیشینه پژوهشها در تعارض است. میدانیم که فقر یکی از عوامل عمده در از دست دادن سلامت روانی است. دلیل این خطا مسئلهای است که آن را محدودیت دامنه در آمار مینامند: نمونه از میان حاشیهنشینان گرفته شده است و بنابراین دامنه نمونه بسیار محدود شده است. هنگامی میتوان ضریب تعیین واقعی را به دست آورد که نمونه در کل جامعه گرفته شود و نه در بخش محدودی از آن. میتوان مثالهای جالبی در این مورد ارائه کرد. با وجود عقل سلیم رابطه قد بازیکنان بسکتبال با تعداد گلهای به ثمر رسیدن آنها رابطه معناداری ندارد. زیرا همه آنها دارای قدی نزدیک به هم هستند و با یک پرش هرچند کوتاه آن اختلاف قد پوشیده میشود. نویسندگان در همین مقاله خطاهای متعدد دیگر نیز مرتکب شدهاند. مثلاً در حالی ضریب تعیین 11% است که در مقاله خود آنها گزارش شده است. آنها بعداً با جمع زدن ضرایب، برای ضریب تعیین مقدار 5/13% را به دست آوردهاند. این اختلاف 5/2% به دلیل آن است که نمیتوان ضرایب همبستگی مجزا را در رگرسیون گامبهگام مجذور کرد و ضریب تعیین نهایی را به دست آورد زیرا متغیرهای وابسته با متغیر ملاک همپوشانی در همبستگی دارند.
8- استفادههای نادرست از شیوههای تحلیل آماری
مهمترین اشکال استفاده نادرست از شاخصهای برازش برای تأیید مدلهای است که این شاخصها هنگامیکه آن مدلها ویژگی علی موردنظر (همرس، میانجی یا مخدوشکننده) را نداشته باشد به تصور نویسنده مقاله به تأیید مدل مدنظر آن میپردازد. همین اشتباه ساده حجم وسیعی از پژوهشها را پدید آورده که همگی نادرست است. عریضی با بررسی 200 پژوهش میانجی رشتههای مختلف در ایران دریافت که رابطه علی موردنظر فقط در سه مقاله بهدرستی مورداشاره قرار گرفته است (عریضی، 2020). اشکال دیگر استفاده از آزمون سوبل در تحلیل میانجی است که بیش از چهار دهه از رد آن در تحلیلهای میانجی گذشته است و متأسفانه در پژوهشهای داخلی همچنان به کار میرود؛ مثال آن در پژوهش پاکنهاد و همکاران(2020) است که برای تأیید تحلیل میانجی از آزمون سوبل برای معنیداری اثر غیرمستقیم استفاده شده است. در این جا باید به یک نظریه مهم در آمار ریاضی اشاره کنیم: هنگامیکه دو توزیع نرمال باشند مجموع آن دو توزیع نیز نرمال است اما حاصلضرب آنها مشخص نیست که نرمال باشد. ازآنجاکه اثر غیرمستقیم ضرب دو ضریب رگرسیون است، مشخص است که نمیتوان از آزمون سوبل که یک توزیع متقارن حول اندازه شاخص در نمونه است استفاده کرد. در این جا باید از توزیع تجربی داده و اندازههای حاصل در آن توزیع و شکلگیری شاخص تأیید به دو دامنه استفاده کرد که میتواند یکی از شکلهای توزیع تجربی از قبیل بوتاستراپ یا جک نایف یا آرایش تصادفی باشد. نمونهای از تحلیلهای نادرست آماری استفاده از مجذور تاوکندال در پژوهش سجاد کریمی و همکاران (2014) است که باید از رگرسیون تعدیلی استفاده میشد.
9- همبستگیهای غیرعادی
ضرایب همبستگی غیرعادی، همواره از تعریف نادرست و یا ابزارسازی نادرست یا انتخاب نادرست ابزار ناشی نمیشود. گاهی هم به دلیل دادهسازی است. یکی از مثالهای بسیار واضح پژوهش حیدری ساربان و همکاران (93) است. در یافتههای آنان رابطه بین تعارضات و اختلافات با رضایت شغلی مثبت است و رابطه سرمایه اجتماعی و رضایت شغلی به سطح 977/ 0 میرسد. سرمایه اجتماعی در این مقاله همه واریانس تبیینکننده رضایت شغلی را در برگرفته است. بهتر شدن شرایط زندگی کاری، افزایش حقوق و ارتقاء به آن چیزی نمیافزایند.
یکی از همبستگیهای غیرعادی در پژوهش موقر و همکاران (2020) است. آنها در صفحه 190 نوشتهاند که هدف از انجام پژوهش مدلی با برازش مطلوب برای تبیین افسردگی بر اساس عوامل جمعیتشناختی و عوامل اجتماعی با نقش واسطهای عوامل شناختی است و مجدداً در صفحه 191 نوشتهاند تورش تجزیهوتحلیل اطلاعات از نوع مدلیابی ساختاری بود که به منظور برازش اولیه مدل از طریق معادلات ساختاری با نرمافزار AMOS و در سطح 05/ 0 آزمون شدند (ص 191 و 192) کاری که آنها هرگز انجام ندادند. آنها از رگرسیون چندگانه استفاده کردهاند و بهغلط آن را رگرسیون خطی نام نهادهاند. این سطح از خطاها را من در هیچ پژوهشی درزمینه تحقیق رابطهای تابهحال ندیدهام.
ازجمله همبستگیهای غیرعادی در پژوهش موسوی و همکاران (2019) است. در این مقاله مدلی بسیار ساده بهصورت مدل پیشانیدها (سن، جنسیت، درآمد، تحصیلات، نحوه تصرف مسکن، ...) و پسایندها (امکانات ساختمان، امکانات محلی، خدمات در دسترس، روابط با همسایگان، مشارکت اجتماعی، مشکلات اجتماعی) ترسیم شده است. این مدل بهوضوح نادرست است. چگونه رضایت از سکونت ممکن است بر ویژگیهای کالبدی آنطور که در شکل (1) صفحه 51 آمده است تأثیر گذارد؟ چون بهصورت طبیعی ویژگی کالبدی است که بر رضایت از سکونت اثر دارد. از طرف دیگر در این مقاله فقط همبستگی خام گزارش شده است (جدول 3، صفحه 57) درحالیکه ویژگیهای کالبدی مسکن و ویژگیهای اجتماعی بهصورت دو عامل مجزا آمده اما هیچ تحلیل عاملی روی آنها انجام نشده است. در مورد متغیرهای مستقل (جدول 4، صفحه 58) نباید همبستگیهای خام گزارش شود. در اینجا چون هیچ فرضیهای وجود ندارد باید از رگرسیونهای چندگانه (در اینجا گامبهگام یا پسرو ) استفاده شود. چون در این مقاله معمولاً رگرسیونهای تأییدی توصیه شده است و رگرسیون چندگانه نقد شده است. اینجا اتفاقاً باید از رگرسیون چندگانه استفاده شود.
البته باید توجه داشت که اگر متغیرهای بعدی افزوده شوند، ممکن است هم خطی ایجاد شود؛ به این معنی که روابط با همسایگان متغیر X1 با خشنودی شغلی y یک رابطه ساده دارد. افزودن مشارکت اجتماعی X2 ممکن است با خشنودی شغلی رابطه داشته باشد اما افزودن X2 علاوه بر آن ممکن است به دلیل رابطه با X1 و نیز رابطه با باقیماندههای مدلی که y را از x پیشبینی میکند بر نتایج تأثیر گذارد. اگر افزودن X2 پیشبینی را بهبود نداد اما همبستگی با X1 و y وجود داشت، در آن صورت اثر برآورده شده X1 کاهش یافته و حتی ممکن است معنیداری خود را از دست بدهد. دلیل آن این است که X1 و X2 همپوشی قابلملاحظهای دارند (X1 بهصورت منحصر بفرد y را پیشبینی نمیکند). بنابراین به دلیل افزایش متغیرهای پیشبین توان آماری کاهش مییابد (درجه آزادی خطا کم میشود). این متغیرها هرچند با یکدیگر میتوانند متغیر ملاک را پیشبینی کنند اما چون توان کاهش یافته، نمیتوانند فرضیه آن را تأیید کنند. این مسئله را همخطی متغیرهای پیشبین مینامند.
از موارد دیگر مقاله زارعی و همکاران (2019) است. در این مقاله ضرایب همبستگی ساده نخست محاسبه شدهاند. در صفحه 153 مدلی ترسیم شده است و ادعا شده که نمودار مسیر است. به جای ضرایب مسیر (ضرایب بتا) همان ضرایب همبستگی بر روی نمودار منتقل شدهاند. در اینجا همین همبستگیها برای نویسنده کافی بوده است (اما نه برای ما). مدل ترسیم شده نه مبتنی بر پیشینه پژوهش و نه دادههای تجربی است و معلوم نیست برچه مبنایی رسم شده است. بعداً جدولی از اثرات مستقیم و غیرمستقیم و اثر کل رسم شده است. در مرتبه سوم این بار اثر مستقیم همان ضرایب همبستگی ساده گزارش شده است و گاهی یک اثر غیرمستقیم هم گزارش شده است که آزمودن معنیداری اثرهای غیرمستقیم هم گزارش نشده است.
10- پیشفرض کاربرد الگوهای رگرسیون خطی برای دادههای رابطهای
در پژوهشهای رابطهای شناخت الگو مشخص کردن تابع انتظار و مشخصههای خطا امری مهم است. برای تابع انتظار ملاحظات عقلی یا نظری مدنظر قرار میگیرد که از طریق آن الگوی مکانیکی تابع انتظار شکل میگیرد که در سادهترین شکل، الگو و برآورد پارامتر با آن تعریف میشود.
این الگو باید برازش کافی با دادهها داشته باشد. معمولاً آن ملاحظات عقلی یا نظری که تابع انتظار را میسازد نادیده گرفته شده و بنابراین یک پیشفرض وجود دارد که الگوهای رگرسیون خطی تابع روابط خطی است. امری که لاجرم بدون دلیل توجیهی بر رگرسیون خطی است. در بسیاری موارد رگرسیون غیرخطی بین دادهها باید در نظر گرفته شود یا اگر دادهها بهصورت دادههای دورافتاده باشند در آن صورت رگرسیون چند کی (بامنی مقدم، خوشگویان فرد، 2004) بیشتر قابل توجیه است.
پیشفرض الگوی رگرسیون خطی که همواره بین متغیرها بدون توجیه عقلانی و منطقی وجود دارد منجر به حجم زیادی از دادههای تولیدشده توسط این الگوهاست، بنابراین کاربرد الگوهای رگرسیون خطی برای همه دادههای رابطهای نادرست است و در بسیاری از موارد ممکن است این روابط غیرخطی باشند.
در پژوهش خداداد کاشی و جاویدی (2012) این سؤال مطرح شده است که آیا آموزش بر فقر خانوادههای ایرانی اثر معنیدار دارد و آیا آموزش میتواند سبب کاهش فقر درآمدی و فقر مسکن و فقر بهداشت شود. روش تجزیهوتحلیل دادهها و تخمین مدل (ص 95) رگرسیون لاجیت و پروبیت است که نادرست است و باید از رگرسیون چندکی استفاده شود. این امر نیاز به بحث بسیار مفصلی دارد که در یکی از شمارههای آتی مجله به آن خواهم پرداخت.
11- تحلیلهای رگرسیون تأییدی و مدل معادلات ساختاری نادرست
تحلیل رگرسیون تأییدی را میتوان به سه دسته کلی تقسیم کرد که به ترتیب رگرسیون تعدیلی، رگرسیون فرونشان و رگرسیون میانجی است هر سه این نوع پژوهشها را میتوان با مدل معادلات ساختاری نیز انجام داد. در ایران تابهحال تحلیل فرونشان در هیچ پژوهشی گزارش نشده است تحلیل تعدیلی در مقالههای رفاه اجتماعی وجود ندارد اما تحلیل میانجی هم در کل پژوهشهای علوم انسانی و هم در پژوهشهای رفاه اجتماعی به کار رفته است. در تحلیل تعدیلی میتوان از رگرسیون سلسله مراتبی استفاده کرد. در ابتدا متغیر اصلی اول و پس از آن متغیر اصلی دوم را وارد معادله رگرسیون کرد و در نهایت حاصلضرب آن دو متغیر را که تعدیل یا تعامل متغیرها را نشان میدهد در معادله رگرسیون وارد کرد. تفاوت این نوع رگرسیون با رگرسیون گامبهگام (یا رگرسیونهای پیشرو و پسرو) در آن است که معادله آن این جمله ضربی را داراست که در تحلیل واریانس معادل تحلیل واریانس چندراهه است.
مدل معادلات ساختاری که تابهحال سه نسل را در طول یک قرن اخیر گذارنیده است اینک به ابزاری ساده در دست پژوهشگرانی تبدیل شده است که زیربناهای آن را بهدرستی نمیشناسند. به دلیل همین ناآشنایی انبوه مقالات زیادی تولید شده است که هیچ مفهوم روشنی ندارد که با کمک گرفتن از عنوان نمایشنامه شکسپیر میتوان آن را هیاهوی بر سر هیچ نامید.
نسل اول تحلیل معادلات ساختاری را گالتون (1888) برای تحلیل عاملی تأییدی پدید آورد که بعداً پیرسون و لی آن را به شکلی استادانه تدوین کردند. نسل دوم را که گام مهمی در مدل معادلات ساختاری است، رایت (1918) پدید آورد که تحلیل مسیر نامیده میشود. این مدل از ترکیب آن دو مدل معادلات ساختاری در نسل سوم پدید آمده است. این مدل، معادلات نسل اول و دوم را تحت عناوین مدلهای اندازهگیری و ساختاری ترکیب کرد که امروزه مبنای پژوهشهای زیادی است که در علوم انسانی به آن ارجاع میشود.
نمونهای از استفاده از معادلات ساختاری به جای رگرسیون در تحلیل تعدیلی را میتوان در پژوهش زمانی و عریضی (202) دید که شاید تنها پژوهشی باشد که از این شیوه به جای رگرسیون تعدیلی در تحلیل دادهها استفاده کرده است. ازآنجاکه معرفی آن در اینجا میتواند به کاربرد بیشتر این شیوه و استفاده از توانمندیهای آن منجر شود معادلات ساختاری مربوط به آن را در این بخش میآوریم.
متغیر با رابطهη3=〖η 1 η〗 2 تعریف میشود و نقش متغیر تعدیلی را نشان میدهد. واریانس بین این متغیرها η KK و کواریانس آنها Ψ KL خواهد بود. در آن صورت بنا بر جروسکوگ و یانگ (1996) معادلات ساختاری برای اثر اصلی و اثر تعاملی شامل چهار معادله است.
برای اثرهای اصلی دو معادله شماره (2)y 1= t 1+λ 1 η 1+ε 1 و شماره (3) y 2= t 2 λ 2 η 2+ε 2 و برای متغیر تعدیلی میتوان معادله شماره (3) y 3= t 3+λ 3 η 3+ε 3 را نوشت. برای اثر تعاملی جروسکوگ و یانگ (1996) معادله زیر را مینویسند که جمله برجستهشده مربوطه به اثر تعاملی است که η 3=〖η 1 η〗 است. اگر متغیر ملاک برنامهریزی برای ورود به دانشگاه y 4 را بر اساس η 1 ، η 2 و η 3 بنوسم، داریم
معادله (4)y 4=t 4+λ 41 η 1+λ 42 η 2+λ 43 η 3+ε 4
و مقدارy 3 برابر (t 2+λ 2 η 2+ε 2 ) (t +λ 1 η 1+ε 1 )است. بنابراین T 3=T 1 T 2 و λ 1=T 2و λ 2=T 1 خاهد بود.
این مدل به لحاظ اصول راهنما شامل تشخیص مدل و در گام دوم گردآوری دادهها و در گام سوم روشهای برآورد و در گام نهایی ارزشیابی و بهبود است. متأسفانه در هیچ یک از مقالهها این اصول راهنما رعایت نمیشود که پرداختن به آنها مستلزم مقاله مستقلی است؛ اما در مورد مرحله اول که رابطه بین متغیرها در یک نمودار تجلی مییابد معمولاً مبتنی بر جهتهای علی در پژوهشهای مبتنی بر طرحهای علیتی از قبیل طرحهای طولی و آزمایشی نیست.
واژه علی که در مدل معادلات ساختاری به کار میرود با جهت نمودارها متفاوت است و علاوه بر آن نموداری که ترسیم میشود مدلهای همارز را نیز شامل میشود و معمولاً پژوهشها از آن ناآگاهند و شگفتزده میشوند که چرا قبل از آنها کسی این مدلها را بررسی نکرده است. غافل از آنکه در مجلههای معتبر بینالمللی داوران قوی حضور دارند که به این مطالب آگاهی دارند. بهعنوانمثال در پژوهش قاسمی و همکاران (1392) که مدل میانجی است، به تبیین رفاه اجتماعی و تأثیر آن بر احساس امنیت در شهر اصفهان پرداخته شده است. مدل میانجی بهصورت زیر است.
مدل فوق یک مدل میانجی است. در مورد مسیر یک که تأثیر سرمایه اجتماعی بر رفاه اجتماعی را نشان میدهد مؤلفین جملاتی از قبیل زیر را نوشتهاند(ص 26) به نقل از زاهدی و دیگران، 2009):
یافتههای تجربی متعدد، اهمیت سرمایه اجتماعی را رد ارتقای سطح توسعه اقتصادی جوامع نشان میدهد و ازآنجاکه سطح توسعهیافتگی بهطور بیواسطه معرف سطح نهاده اجتماعی است ارتباط میان سرمایه اجتماعی و توسعه را میتوان به ارتباط میان سرمایه اجتماعی و رفاه اجتماعی تأویل کرد و نتیجه گرفت که وجود سرمایه اجتماعی بالا میتواند سطح بالاتری از رفاه اجتماعی را تأمین کند.
آیا نمیتوان جمله آخر را به این صورت نوشت که رفاه اجتماعی بالاتر میتواند سرمایه اجتماعی بیشتری را تأمین کند و ازآنجا مسیر یک را کاملاً در جهت برعکس نوشت. در این صورت هم رفاه بر سرمایه اجتماعی و هم بر احساس امنیت تأثیر میگذارد و نمیتوان آن را مدل میانجی نامید. این یک مدل همارز است که مدل مخدوشکننده نام دارد. بهاینترتیب میتوان دید که با تغییر در کاربرد زبان میتوان بهسادگی مدل را تغییر داد و یک مدل همارز از آن را ساخت. جهتهای مورداشاره کاملاً ساخته زبان خصوصی است و یکبار دیگر گفتگوی هامپتی دامپتی را به یاد میآورد. تنها هنگامی میتوان این جهات را ترسیم کرد که مبتنی بر پیشینه پژوهشهایی باشد که در آن طرحهای پژوهشی بهصورت مطالعات طولی یا آزمایشی ارائه شده باشد. حال جمله زیر از فیتنر پاتریک، 1381) را مدنظر قرار دهید:
در رویکردهای نوین رفاه بر مسئولیت جامعه در قبال آحاد مردم تأکید شود که شامل شادکامی، تأمین امنیت و ترجیحات و نیازها و رهایی و مقایسه نسبی است.
مجدداً این جمله در جهت مسیر دو در مقاله مورد استناد قرار گرفته است. درحالیکه این جمله در مورد تأثیر رفاه بر احساس امنیت به ما چیزی نمیگوید. تنها میگوید که رفاه اجتماعی ازجمله شامل احساس امنیت است. بهاینترتیب جملاتی که در پیشینه نقل میشود نمیتواند این مدل را توجیه کند. همچنین در صفحه 4 آنها نظر شخصی خود را با این جمله بیان کردهاند که کارآمدی سیاستهای رفاهی به مقدار سرمایه اجتماعی در جامعه مربوط است. ازآنجاکه این جمله دیدگاه آنان است من میتوانم جملهای در جهت برعکس مسیر یک بنویسم که سرمایه اجتماعی به مقدار زیادی تابع رفاه اجتماعی در جامعه است. جملهای که نادرست به نظر نمیرسد. از طرف دیگر رابطه رفاه اجتماعی و امنیت یعنی مسیر دو را با این جمله مورد استناد قرار دادهاند.
به نقل از یزدانی، 1382:
یکی از پیامدهای اندیشهای درزمینه رفاه اجتماعی به نظریه اخلاقی دولت هگل بازمیشود. بر مبنای این نظریه، وظیفه اخلاقی دولت، حفظ امنیت و ایجاد اعتماد عمومی به کارکردهای جامعه در جهت حفظ منابع یکایک افراد جامعه است و عدالت نیز در این زمینه نقش به سزایی بر عهده دارد.
این جملات که در صفحه 7 مقاله آنها آمده برای توجیه مسیر دو در نمودار میانجی آنان است؛ اما میتوان از این جمله برداشت کرد که امنیت بر رفاه اجتماعی تأثیر میگذارد. امری که مدل میانجی را به یک مدل همرس تبدیل میکند. این مدل همارز با مدل میانجی است بنابراین مدل آنان را توجیه نمیکند. همچنین جملهای که در صفحه 4 نوشتهاند نیز به دلیل توجیه مدل میانجی غیر از یک زبان خصوصی نیست.
رفاه اجتماعی را نمیتوان صرفاً توسط مؤلفههای اقتصادی و مادی تضمین کرد و علاوه بر آن باید منابع جامعه مدنی ازجمله سرمایههای اجتماعی و گروههای گوناگون مردم را فعال و بسیج کرد.
چنانکه دیده میشود نمیتوان مدل میانجی را توجیه کرد و تعجبی ندارد که در این زمینه در سطح بینالمللی مقالهای ارائه نشده است؛ زیرا آنان زیربناهای توجیه چنین معادلاتی را نه زبان خصوصی که زبان علمی میدانند که در مجلات علمی با داوریهای دقیق بررسی میشود.
بهکرات مؤلف مقاله حاضر دیده است که پژوهشگران تعجب میکنند که چرا قبل از آنان کسی به فکر این رابطهها نیفتاده است. هنگامیکه به دنبال رابطههای میانجی میگردیم اکثر این مقالهها را ایرانیان نوشتهاند. حال به دلیل روانشناختی این مقالهها بازمیگردیم. پس از ورود دادهها به نرمافزارهای تحلیل مدل معادلات ساختاری پژوهشگران با دادههای برازش به سهولت آن را تأیید میکنند. بهاینترتیب این مقالهها از سه فرایند جملهپردازی در قالب زبان خصوصی، ورود دادهها و برازش به مرحله تأیید داده میرسد؛ درحالیکه شاخصهای برازش فقط پس از توجیه مدل پیشنهادی بر مبنای دقیق و استوار یعنی نظریههای شناخته شده یا طرحهای پژوهشی از قبیل طولی و آزمایشی امکانپذیر است.
در تفسیر دادهها نیز پژوهشگران دارای مشکلات جدی هستند. به این معنی که تصور میکنند توانستهاند مدل برساخته از زبان خصوصی را تأیید کنند و حالآنکه مدلهای همارز دیگری وجود دارد که با این شاخصها عیناً تأیید میشوند. اگر پژوهشگر بخواهد مدلهای همارز را رد کند از قبل باید توجیه نظری دقیقی برای مدل موردنظر ارائه داده باشد وگرنه امکان رد آن در مرحله پسین وجود ندارد.
در پژوهش قاسمی و همکاران متأسفانه تحلیل آماری نیز کاملاً غلط است. آنها ابتدا سه ضریب همبستگی ساده در مسیر یک و دو و سه را بررسی کردند که هر سه معنیدار بوده است. میدانیم که این سه فرضیه در مدل بارون و کنی (1986) فقط سه فرض اولیه هستند و فرض چهارم بسیار مهمتر است. با کنترل متغیر میانجی رابطه بین متغیر پیشبین و ملاک ناپدید میشود. آنها این فرضیه را بررسی نکردهاند و با نیمهکاره رها کردن تحلیل رگرسیون ناگهان از مدل معادلات ساختاری سعی کردند تحلیل میانجی را که نتوانستهاند در تأیید آن موفق باشند فقط بهصرف شاخصهای برازش تأیید کنند. یعنی تحلیل تأییدی در حالتی که مدل اصلی توجیه نشده است که کار کاملاً غلطی است. اثر غیرمستقیم یا میانجی که باید بر مبنای توزیع تجربی بوتاستراپ یا جک نایف انجام گیرد نیز گزارش نشده و بنابراین اصولاً مشخص نیست که اثر غیرمستقیم معنیدار است یا خیر. بهترین طرحهای تحلیل میانجی عبارت است از کاربرد میانجی در پژوهشهای آزمایشی است (کلاهدوزان، 2020).
12- ناهمخوانی معادله ریاضی زیربنایی با تحلیل آماری
معادله ریاضی باید هماهنگ با دادهها و طرح پژوهشی باشد که در تحقیق ارائه شده است. مثال عالی از این معادلات را میتوان در آمیگو و همکاران (2008) یافت که مجموعهای از معادلات برای صرف دارو در مغز در تصویرنگاری مغناطیسی از آن نوشتهاند. معلوم است که برای آنکه مشخص شود این معادلات با واقعیت انطباق دارند در مرحله بعدی باید دادههای شبیهسازی شده از انسان تطبیق داده شود.
کیوانآرا همکاران(2016) نیز معادلهای برای هوش مصنوعی نوشتهاند و آن را با ویژگی شخصیتی برونگرا هماهنگ کردهاند. سپس دادههای شبیهسازی شده را با آن منطبق ساختهاند که مغز افراد برونگرا این دادهها را مصرف میکنند. آنها این پژوهش خود را برای آزمون نظریه آیزنک مورداستفاده قرار دادهاند که طبق آن نحوه تأثیر داروها در مغز افراد برونگرا به شکل خاصی است. سپس دادههای مربوط به افراد معتادی که شخصیت برونگرا داشتهاند را با این مدل انطباق دادهاند. این دو شاهد از استفاده موفق از معادلات ریاضی است و در غیر این حالات استفاده از آن قابل توجیه نیست.
گاهی معادله ریاضی زیربنایی با تحلیل آماری ناهماهنگ است. مثلاً معادله زیربنایی تحلیل رگرسیون تعدیلی را پیشنهاد میکند اما پژوهشگر از تحلیل رگرسیون چندگانه استفاده کرده است. نمونه آن مقاله رنانی و مؤیدفر (1999) است که آن را در سطح پایینی در مقالات سرمایه اجتماعی قرار میدهد. بااینحال به دلیل محدودیت فضا فقط به بعضی از این خطاها در این مقاله اشاره میکنم. نخست به خطاهای تحلیل دادههای آن پرداخته و سپس فضای مفهومی آن را موردنقد قرار میدهم.
از نظر روانسنجی اگر ابزارها دارای پایایی و اعتبار نباشند، نباید به دادههای آن اعتماد کرد. در پژوهش آنان روی هم 35 سؤال مربوط به سه مقیاس است. درحالیکه فقط یک ضریب پایایی برای مجموع سه مقیاس گذاشته شده است. گیفورد در کتاب معروف روانسنجی خود تعداد 35 سؤال کاملاً نامربوط به هم را انتخاب کرده و روی یک نمونه آنها را اجرا میکند. او ضریب پایایی 75/ 0 را به دست میآورد که کاملاً بیمعنی است. دلیل آن این است که طبق یک قضیه معروف در روانسنجی با افزایش تعداد سؤالات ضریب پایایی افزایش مییابد. از طرف دیگر آنها به یک مدلسازی ریاضی میپردازند که در تحلیل دادههای آنها حضور ندارد و کاملاً نامربوط با شیوه تحلیل دادههای آنها است.
آنها نوشتهاند که افراد علاوه بر آن که از ویژگیهای هویتی و معرفتی فرد بهصورت مستقل تأثیر میپذیرد، تحتتأثیر اثرات متقابل این ویژگیها بر یکدیگر نیز قرار میگیـرند. بیان ریاضی این تفسیر میتواند بهصورت رابطه زیر مدلسازی شود:
در این جا یک رابطه ضربی تعریف شده است که مستلزم تحلیل تعدیلی است. در متن مقاله آنها این رابطه ضربی که بسیار مهم هم هست ناپدید شده است. درواقع نتایج آنها به کمک تحلیل حداقل مجذورات (OLS) و رگرسیون معمولی بوده است. درحالیکه نیاز به رگرسیون تعدیلی داشته است. معلوم نیست چرا آنها چنین فرمولی را که مربوط به متن دیگر است در اینجا قرار دادهاند.
مؤلفههای سرمایه اجتماعی بهصورت پایبندی به هنجارها، قابلاعتماد بودن و حـضور فعـال در شبکههای اجتماعی بوده است. بنابراین ویژگیهای افراد جامعه در ارتباط با سه مؤلفه فـوق، در ماتریس دیگر قابل جمعآوری است که در آن تعداد سطرها به تعـداد سـه مؤلفه سرمایه اجتماعی ـ پایبندی به هنجارها، قابلاعتماد بودن و حضور فعال در شبکههای اجتمـاعی و تعداد ستونها به تعداد افراد جامعه خواهد بود. در ماتریس D ویژگیهای افراد در ارتباط با مؤلفههای سرمایه اجتمـاعی را بـه ایـن مفهوم که هر فرد چه اندازه به هنجارها پایبند است؛ چه قدر قابلاعتماد است و تا چه حد در شبکههای اجتماعی مشارکت میکند نشان میدهد.
حاصلضرب ایـن مـاتریس در ماتریس «تعامل ارزشهای درونی افراد جامعه» بهصورت: (6) D*Y=G ماتریس درجه برخورداری افراد جامعه از مؤلفههای سرمایه اجتمـاعی اسـت کـه در تعاملات و مبادلات اجتماعی قابلیت انباشته شدن و تبدیل به سرمایه اجتماعی است، یعنی ماتریس G را نشان میدهد.
در مقاله مویدفر و همکاران () هویت دینی مطرح شده است که آن هم جنبه کاملاً انفعالی و برونزاد دارد. هویت ابعاد بسیار مهم و زیربنایی دیگری دارد که عبارت از طبقه اجتماعی، جنسیت و قومیت علاوه بر هویت دینی است. این هویتها هم با یکدیگر اثر تعاملی دارند که در پژوهشهای اجتماعی بهعنوان مدلسازی تعامل متقاطع شهرت یافته است (مثلاً نگاه کنید به سنگ و همکاران، 2015). درواقع هویت اجتماعی از تعامل این متغیرها شکل میگیرد. روشهای تعامل متقاطع درواقع باید کاملتر نوشته شود. درواقع معادله (1) را به شکل کاملتر میتوان بهصورت زیر درآورد:
همانطور که گفته شد معادلهای که مویدفر و همکاران () نوشتهاند ربطی به تحلیل دادههای آنها ندارد؛ چون اصولاً رگرسیون تعدیلی انجام ندادهاند. هر رابطه ضربی از نوعی که آنها نوشتهاند یک رابطه تعاملی است اما من پیشنهاد میکنم که یک رگرسیون سلسله مراتبی از نوع تعدیلی انجام شود تا مشخص شود آیا ماتریس حاصل بیشتر تحت تأثیر (الگوی مارکسی)، (الگویهانتیگتونی، مویدفر) یا است. روشهای تحلیل ازایندست بسیار دشوارتر از معادله (2) بوده و درزمینههای متفاوت در وارنر و براون ، 2011 شرح داده شدهاند.
13- تغییر ارجاع به پیشینهساختگی و مطالعه ناکافی پیشینه
در بسیاری از پژوهشهای مربوط به متغیر سوم ایجاد ارتباط بین متغیرها فقط از طریق رابطهای است که در ذهن پژوهشگر تصور میشود و کاملاً برساخته اوست و با واقعیت آن رابطه منطبق نیست. بهعنوان نمونه به پژوهش اصغری و همکاران (2021) که در بخش پنج به آن پرداختهایم بازمیگردیم. در این تحقیق سعی میشود رابطه بین سه متغیر خودمهارگری و شفقت به خود و فداکاری همسر بهصورت یک رابطه میانجی توجیه شود. طبق این نوع پژوهشها نخست سه متغیر بیان شده و تعاریف آن ارائه میشود و سپس رابطه بین دوبهدوی متغیرها باید با پژوهشهای پیشین توجیه شود. پژوهشگر بدون آنکه بداند که معنی اینکه متغیری عامل تأثیرگذار حفاظتی دارد به معنی آن است که آن متغیر تعدیلی است، بیان میکند که خودشفقت بین دو متغیر دیگر نقش میانجی دارد و با اشاره به پژوهش ممتازی به نظریه سپر محافظتی استناد میکند.
همانطورکه قبلاً در همین مقاله بیان شد نظریههای سپر حمایتی همواره نقش تعدیلی و نه میانجی دارند. پژوهشگرانی که به تحلیل متغیر سوم میپردازند و نیز داوران آنها باید بتوانند بین عبارتهای زبانی و استفاده از تحلیلهای آماری تناظری برقرار کنند. پژوهشگر اما در همان صفحه به نقل از بکدان و همکاران (2016) مدلی را پیشنهاد میکنند که خودشفقتی (شفقت بر خود) بهصورت متغیر میانجی بین دلبستگی اضطرابی و قدردانی از بدن است.
اینکه خودشفقتی متغیر میانجی بین متغیرهای دیگری باشد توجیهکننده اینکه در یک تحلیل میانجی بهعنوان متغیر ملاک قرار گیرد نبوده و دو متغیر دیگر نیز هیچ ارتباطی به این پژوهش نداشته و بنابراین منابعی نیستند که توجیهکننده رابطه میانجی باشند. استفاده از پژوهشهای نامربوط در بسیاری موارد منجر به ساخت پژوهشهای با متغیر سوم (میانجی، فرونشان، مخدوشکننده و همرسان) بدون مفهوم و بیمعنی شده است. پژوهشی که حداقل بین دو متغیر در تحلیل میانجی در پژوهش آنان ارتباط ایجاد میکند پژوهش اوزیل و هفتز (2014) است. نویسندگان یک رابطه همبستگی ساده بین دو متغیر پژوهش خود را از آن نقل میکنند که خودمهارگری بالا منجر به خودشفقتی بیشتر میشود که درواقع متغیر ملاک و پیشبین پژوهش آنهاست.
متأسفانه این ارجاع غیرواقعی است و پژوهش اوزیل و هفتز (2014) یک پژوهش آزمایشی است که در آن متغیر شفقت به خود وجود ندارد. در پژوهش مذکور با دستکاری خودمهارگری سعی شده که رفتار عقلانی در تصمیمگیریهای اقتصادی بررسی شود و ارجاع به شفقت به خود کاملاً نادرست بوده و فقط برای توجیه میانجی استفاده شده است. این مسئلهای است که معمولاً در تحلیل میانجی دیده میشود. چون توجیه رابطه بین متغیرها مهمترین گام در این تحلیل است فقدان آن در بیشینه را، با ارجاع نادرست میتوان جبران کرد.
آنها با ارجاع به پژوهش سلطانزاده (2012) رابطه ساده بین شفقت به خود و رفتارهای فداکارانه را متذکر شدهاند و به نقل از استفنسون (2014) بیان کردهاند که پاسخ همدلانه از سوی همسر بهمثابه یک ضربهگیر در برابر اثرات منفی عمل میکند که مجدداً تحلیل آماری این فرضیه اثر تعدیلی و نه اثر میانجی است. بنابراین در پیشینه هیچ دلیل موجهی برای رابطه میانجی وجود ندارد و نمیتوان این مدل را حتی بر پایه پیشینهها تجربی توجیه شده دانست.
متأسفانه مقالات متعددی در ایران وجود دارد که با چنین توجیهات نادرستی سعی میکنند رابطه با متغیر سوم را بهگونهای توجیه کنند و بسته به اراده پژوهشگر ممکن است بهصورت متغیر میانجی یا تعدیلی و یا فرونشان درآیند. شفقت به خود شامل شش زیر مقیاس است که مهربانی به خود، قضاوت خود، ذهنآگاهی، همانندسازی، اشتراکات انسانی و انزوا این زیرمقیاسها را شکل میدهند. پژوهشگران آن را به یک متغیر تقلیل دادهاند تا از پیچیدگی آماری آن بکاهند اما ناخواسته دچار خطای دیگری شدهاند؛ اینکه زیرمقیاسها جمعپذیر نیستند و بنابراین نمیتوان آن را بهصورت یک متغیر یکپارچه درآورد و در بحث و نتیجهگیری از آن دچار خطایی میشوند که توجیهپذیر نیست. پژوهشگران در صفحه 136 مینویسند که جنبههای مثبت شفقت به خود چون مهربانی به خود، حس انسانیت مشترک، ذهنآگاهی بهصورت مثبت و سختگیری و انتقاد از خود میتواند دارای جنبه منفی بوده و احساس دوگانه را در فرد تقویت کند. مثلاً پژوهشگران در توجیه رابطه میانجی نوشتهاند:
از طریق مهربانی به خود میتواند تصویری مثبت ایجاد کند و این تصویر مثبت از خود مطابق با این مفهوم که فردی است نگران همسر ... ممکن است فعالیتها و اموری را انجام دهد که تمایل و رغبتی به آنها ندارد؛ اما چون با همسرش احساس خوبی خواهند داشت، فرد از طریق آگاه بودن از تجربیات در زمان حال حاضر به اهداف طولانیمدت دست خواهد یافت.
در اینجا دو متغیر شفقت به خود و فداکاری ادراکشده همسر به ترتیب دارای شش و دو زیر مقیاس است و چون در این پژوهش این زیرمقیاسها در تحلیل میانجی وارد نشدهاند پژوهشگر ناگزیر به جای آنکه بر مبنای دادهها سخن گوید تصورات خود را شرح میدهد بدون آنکه پشتوانه پژوهش از دادههای خود را داشته باشد؛ مثلاً خودشفقتی فقط به مهربانی تقلیل مییابد که یکی از زیرمقیاسهاست و نمیدانیم که رابطه این زیرمقیاس با متغیرهای دیگر چگونه است.
درعینحال چون فداکاری ادراکشده از همسر و فداکاری خود فرد که دو زیرمقیاس هستند با یکدیگر ترکیبشده معلوم نیست که در هر مورد چه تأثیری بر خودمهارگری داشته است. مضاف به اینکه به نظر میرسد خودمهارگری بر رفتار فداکارانه فرد اثر دارد و نه برعکس. زیرا فرد باید از لذتهای خود به نفع همسر چشم پوشد که نیاز به خودمهارگری بالایی دارد. درواقع این رابطه در تحلیل متغیرهای سوم نه تحلیل میانجی بلکه تحلیل همرس است و بنابراین همه این گفتگو که مربوط به تحلیل میانجی است بیاعتبار میشود.
هیچ مزیتی بر میانجی گرفتن رابطه بین متغیرها وجود ندارد و درک عقلایی بین آنها به تحلیل همرس که مدل همارز میانجی است نزدیکتر است. بهخصوص با توجه به آنکه مدل همارز تحلیل میانجی آنها حتی توسط پیشینههای تجربی نیز پشتوانهای ندارد و کاملاً همبستگی خیالی در ذهن پژوهشگر پدید آمده است که تابع زبان خصوصی است و آسیب در تحلیل متغیرهای سوم از همینجا ناشی میشود.
پژوهشگران فقط رابطه ساده بین متغیرها را گزارش کردهاند که به نظر در سطح بسیار بالایی است و تا حدی مشابه همبستگیهای غیرعادی است. خودمهارگری با مهربانی (53/ 0=r) با اشتراکات انسانی (48/ 0=r) ذهنآگاهی (53/ 0=r) شفقت به خود 31/ 0=r (ص 132/ جدول 2) بااینحال در مورد این همبستگیهای ساده بحثی نشده که چرا بعضی از آنها مثبت و بعضی منفی است و هنگامی که به سراغ متغیر سوم میروند با شاخص برازش رابطه میانجی را تأیید شده میبینند که به دلیل ناآگاهی آنان از مدلهای همارز است. در جدول 3 ادراک رفتارهای همسر و شفقت به خود با یک ضریب همبستگی ساده گزارش شده است. درصورتیکه اولی شامل دو زیرمقیاس و دومی شامل شش زیر مقیاس است و این همبستگی ساده در شناسایی رابطه بین متغیرها نمیتواند توجیهکننده باشد. بخصوص اینکه ادراک رفتارهای همسر یک متغیر در مورد خود فرد و همسر او است که رفتار دوتایی را گزارش میکند و بر هم نهی آنها کاملاً با فلسفه این متغیر مغایرت دارد چون یک نفر فداکاری میکند و دیگری که ابژه این فداکاری است نمیتواند همزمان فرد فداکار باشد. شفقت نیز دارای مقیاسهایی است که با یکدیگر در تضاد هستند و جنبههای مثبت و منفی شفقت را شرح میدهند. جمعپذیری آنها به لحاظ روانسنجی نادرست و امکان تحلیل از این متغیرها را از میان میبرد. در واقع آنچه به جای آن مینشیند نوعی زبان خصوصی بیحاصل است.
بعضی مواقع پژوهشگران برای توجیه متغیر سوم به پیشینهای متوسل میشوند که آن را بهدرستی مطالعه نمیکنند. قبلاً به پژوهش اوزیل و هفتسز (2014) اشاره کردیم که برای توجیه رابطه بین کنترل خود و شفقت خود مورد استناد آنها قرار گرفته بود؛ درحالیکه چنین رابطهای در آن پژوهش وجود ندارد و بحث دیگری در آن پژوهش مدنظر قرارگرفته که متغیر کنترل خود را به متغیر فداکاری همسر مرتبط میکند؛ اما کاملاً در جهت برعکس رابطهای که پژوهشگران در تحلیل میانجی خود گنجانیدهاند. متغیر کنترل خود موردعلاقه امانول کانت، فیلسوف بزرگ آلمانی، بود. او در کتاب «نقد عقل ناب» خود این دیدگاه را مطرح کرد که کنترل، خود منجر به فعالسازی عقل ناب میشود که منفعت شخصی را هدایت میکند. این رویکرد بهصورت غریزه خودخواهی پدیدار میشود که در متون اقتصادی محرک منفعت شخصی است؛ رویکردی که بعداً آین رایند (1963) آن را نگرهپردازی کرد که در نمودار زیر دیده میشود.
همانطور که دیده میشود برخلاف استدلالهای نویسندگان مقاله که بر هیچ نظریهای استوار نیست خودکنترلی نه با متغیر فداکاری همسر که ضد رفتار خودخواهانه است، بلکه با رفتار خودخواهانه مرتبط است.
ممکن است نویسندگان مقاله بتوانند با جملهپردازی برعکس آن را توجیه کنند. درواقع در مورد هر دو متغیری در عالم میتوان بهنوعی مطلب ارائه داد که آنها را در هر جهتی که میخواهیم به هم مربوط کنیم. اما اگر از نظریهها یا فرضیههای علمی استفاده کنیم ممکن است همه آنها نادرست باشند و این ازجمله آن موارد است.
پژوهشگران بین خودمهارگری و رفتار فداکارانه همسر ضریب همبستگی 53/ 0 را گزارش دادهاند درصورتیکه بر مبنای نظریه مقالهای که بهعنوان پیشینه آوردهاند این همبستگی قابل توجیه نیست. کاری که آنها میتوانستند انجام دهند عدم ارجاع به این مقاله بود که میتوان آن را سوگیری پیشینه مثبت (عریضی و فراهانی، 2008) دانست؛ اما آنها نوشتهاند که رفتارهای فداکارانه همسر میتواند نقش مؤثری در خودمهارگری افراد داشته باشد (ص 140). آنها باید با ارجاع به این نظریه توجیه میکردند که رابطه متغیرها در جهت برعکس است و نه آنچه آنها فرض کردند. ارجاع به پیشینه در پژوهش آنها در بقیه مواقع کاملاً به مدل آنها بیربط است. مثلاً چگونه پژوهش خستهمهر که فداکاری همسر را بهعنوان متغیر میانجی بین کیفیت زوجی و دلبستگی آورده میتواند مورداستفاده پژوهشگران قرار گیرد؟ آنها همچنین یافتههای خود را هماهنگ با تانجنی و همکاران (2004) و صالح حسینی (2015) آوردهاند که در هر مورد نمیتوان آن یافتهها را به این کار نسبت داد.
بحث
در پژوهش حاضر بهطورکلی دریافتهای نادرست از پژوهشهای رابطهای و ارائه آن در مجله رفاه اجتماعی مورد بررسی قرار گرفته است. پرواضح است که پذیرش یک مقاله در مجله پایان کار نیست و حتی بعد از چاپ مقالهها ممکن است ریتراکت شوند. نویسنده این مقاله، برخی از این مقالهها را سزاوار ریتراکت شدن میداند و در این جا به آنها اشاره میکند. در آخرین کتاب نگارش وی ، فصل مهمی به ریتراکت اختصاص یافته است. او این فصل را با معروفترین نویسندهای که هر دانشجوی روانشناسی وی را میشناسد یعنی هانس یورگن آیزنک آغاز کرده است. کسی که در یکی از کتابهای سهگانه معروفش یعنی واقعی واقعیت و خیال در روانشناسی (سومین کتاب) نوشته بود:
دو کتاب پیشین را اغلب «بحثِانگیز» به شمار آوردهاند. در وقع خود من به این لقب «بحثانگیز» چنان عادت کردهام که هر وقت رئیس یک جلسه هنگام معرفی من اشارهای به آن نمیکند نوعی احساس محرومیت به من دست میدهد.
اینک بیش از شصت مقاله او با واژه Retract که بر صفحات مقالهاش و با حروف درشت آمده رد شده است. کلمه Retracter فرانسوی است که در قرن چهارم به معنی بازگرداندن به عقب بوده است که در لاتین rectractus به همین معنی گرفته شده است. کلمه لاتینی retractionem هم به معنی تردید و هم به معنی لغو است. سنت آگوستین کتابی با عنوان Retractions (بازپسگیری) نوشته است که به معنی اصلاح نوشتههای قبلی اوست. کلمه ریتراکت درواقع از او گرفته شده است و اینک در متون روش تحقیق بهعنوان اصطلاحی فنی به کار میرود.
میدانیم که این جنبش جدید از ورزش و پسگیری مدالهای ورزشکاران متقلب آغاز شده است (بهطور مشخص بن جانسون، متولد 1961). عریضی (1401) هفت توصیه برای کاهش ریتراکت (صفحات 129 تا 132) آورده است. خطای آیزنک از جایی آشکار شد که آیزنک سعی کرد با دادههای ساختگی نشان دهد که یک میانجی که او آن را شخصیت مستعد سرطان نامیده بود سبب سیگارکشیدن میشود و خود سیگار تأثیری بر سرطان ندارد. درواقع برای ریتراکت شدن مقالههای او تلاش بسیاری انجام شد.
در زیر در ستون آخر به مقالههایی که شایسته ریتراکت شدن هستند هم اشاره شده است:
ردیف دریافت نادرست خطا دریافت بخش مربوط در مقاله نوع خطا آیا شایسته ریتراک هست؟
| (I)I | PQ -Q |
اگر P، آنگاه Q نقیض Q |
(I)II |
| -P | بنابراین، نقیض P |
مثلاً اگر باران ببارد، زمین تر میشود. اکنون زمین تر نیست. پس باران نباریده است. ولی مغالطه وضع تالی بهصورت زیر است.
| Q P Q |
| P |
نمونه این مغالطه آن است که با دیدن زمین تر نتیجه گرفته شود که حتماً باران آمده است. پیشفرضی که مبنای برازش مدل در تحلیل میانجی (واسطهای) است این است که هرگاه تحلیل میانجی درست باشد (P) آنگاه برازش دادهها وجود دارد (Q) اما اگر دادهها برازش داشته باشند (Q) لزوماً به معنی درستی تحلیل میانجی نیست. چنین استدلالی همان وضع تالی است که دیدیم بیاعتبار است. فقط اگر برازش وجود نداشته باشد (-Q) میتوان تحلیل میانجی را رد کرد. نهفقط در مورد تحلیل میانجی که در معادلات ساختاری نیز از شاخصهای برازش مطلوب برای تأیید فرضیههای پژوهشی استفاده شده است. شاخصهای برازش نمیتوانند در غیاب یک استدلال موجه درباره جهت بین متغیرها، آن را تأیید کنند. این استدلال موجه به طرح پژوهش مربوط است که البته در طرح رابطهای موجه نیست.
بهغلط تصور میشود که اگر شاخصهای برازش، مدلی را تأیید کنند، آن مدل کاملاً درست است. در این مورد دو اشکال وجود دارد: نخست اینکه اگر طرحهای پژوهش از نوع طولی یا آزمایشی نباشد شاخصهای برازش نهفقط آن مدل بلکه مدلهای همارز آن را نیز تأیید میکند (تارکا ، 2018). مثلاً در پژوهش اصغریکماء و همکاران (2021) میانجی به شکل مدل 1 مطرح شده است. مشکل این است که شاخصهای برازش نه فقط این مدل بلکه دو مدل همارز آن یعنی مدل همرس و مدل مخدوشکننده را نیز همزمان تأیید میکند (مدل 2 و 3).
مدل 1- مدل میانجی بین متغیرهای پژوهش

مدل 2- مدل همرس بین متغیرهای پژوهش

مدل 3- مدل مخدوشکننده بین متغیرهای پژوهش

مدل 2- مدل همرس بین متغیرهای پژوهش
مدل 3- مدل مخدوشکننده بین متغیرهای پژوهش
این سه مدل همارز هستند؛ یعنی شاخصهای χ2 و درجه آزادی و CF و GF و RMSEA آنها یکی است. این شاخصها برخلاف دیدگاه نویسنده که تصور میکند مدل 1 را تأیید کرده است همزمان مدل 2 و 3 را نیز تأیید میکند و پژوهشگر نمیتواند با استفاده از شاخصهای برازش، تنها یکی از آنها را تأیید کند. هنگامی میتوان جهتگیری علی را در تأثیر شفقت به خود بر ادراک رفتارهای فداکارانه همسر تعیین کرد که یا از طرح پژوهش آزمایشی یا از طرح پژوهش طولی استفاده شده باشد، یا مبتنی بر نظریهای باشد که میتواند خود آن را در پژوهشی مستقل نگرهپردازی کرده باشد. اگر آن نظریه مبتنی بر یافتههای رابطهای باشد هرچند ضعیف اما قابل استنباط است اما نمیتوان با استدلالهای کلامی از نوع هامپتی دامپتیوار نتیجهگیری کرد. متأسفانه گاهی از این استدلالهای کلامی فراتر رفته و نتیجه تحقیقهای دیگر را برای توجیه مدل خود به کار میبرند.
در اینجا مسئله سوگیری (مثل سوگیری پیشینه خوب و سوگیری نتایج مثبت، نگاه کنید به عریضی و فراهانی، 2008) وجود دارد یعنی تنها تحقیقاتی را ذکر کنند که در جهت مدل میتوان آن را بکار گرفت که اکثراً نابسنده است؛ اما گاهی (مثل همین مقاله) نتایجی را به تحقیق نسبت میدهند که در آن وجود ندارد. در بخش دیگر به آن بازخواهم گشت. در آن صورت نیز بین مدل 1 و مدل 2 یعنی مدل میانجی و همرس نمیتوان تمایز قائل شد مگر اینکه با طرح طولی یا آزمایشی نشان داده شود که ادراک رفتارهای فداکارانه همسر بر خودمهارگری تأثیر دارد.
به لحاظ مفهومی هر سه مدل قابل توجیه است. مثلاً اگر فرد خودمهارگری بالا داشته باشد آیا در طول زمان رفتارهای فداکارانه همسر را به دنبال نخواهد داشت؟ درواقع رابطه متغیرها در هر دو جهت امکانپذیر است. پژوهشهایی که در آنها میزان و درجه آزادی و CF و GF و RMSEA از یکدیگر کم میشوند و بر مبنای این تفاضل یکی بر دیگری ترجیح داده میشود در اساس همارز نبوده و این تفاضل صفر نمیشود.
در آنجا میتوان از ترجیح یک مدل بر مدل دیگر سخن گفت. آن نوع مدلها، مدلهای رقیب نامیده میشود. درعینحال امکان بیشتری به لحاظ مفهومی هست که خود مهارگری متغیر تعدیلی بین ادراک رفتارهای فداکارانه همسر و شفقت به خود باشد. درواقع افراد با خودمهارگری بالا میتوانند همزمان با شفقت به خود، رفتارهای فداکارانه همسر را ارتقا دهند و رابطه بین آنها از این رابطه در افراد با خود مهارگری پایینتر است. دلیل آن این است که افراد با خودمهارگری بالاتر بوده و بنابراین کمتر از گرایش به خود خارج میشوند. بهتبع آن در ادراک رفتارهای فداکارانه همسر ضعیفتر خواهند بود (یادداشت 1). بهعبارتدیگر در ارزشهای خودتقویتی (شوارتز 2003) و خودمرکزی (دامبران و رایکا ، 2012) نمره پایینی دریافت میکنند.
جالب آن است که اصغریکماء و همکاران (2021) در پژوهش خود از تحلیل مسیر استفاده کردهاند که در آن تحلیل تأییدی و شاخصهای برازش بیمعنی است. درواقع فقط در مدل معادلات ساختاری که از دو بخش سنجشی و ساختاری تشکیل شده است تحلیل تأییدی قابل انجام است. در تحلیل مسیر این کار بیمعناست. اما اگر این پژوهشگران از مدل معادلات ساختاری استفاده کرده بودند مسئله نیز تفاوتی نمیکرد و همچنان امکان نتیجهگیری علی وجود نداشت. فقط در صورت استفاده از طرحهای آزمایشی یا طولی یا نظریهای استوار به دادههای پژوهشی امکان چنین نتیجهگیری وجود داشت. دلیل آن این است که مدل معادلات ساختاری و مدل تحلیل مسیر چون صرفاً رابطه را بیان میکنند نسبت به جهتگیری متقارن هستند و هر شکلی از نوشتن معادله این تقارن را حفظ میکند. در بخش دیگر مجدداً به این مقاله بازخواهیم گشت تا نشان دهیم ارجاع به پیشینه تا چه حد در آن ضعیف است.
در پژوهش دیگر گودرزی و همکاران (2021) جملهای که در اکثر پژوهشهای شبیه به آن وجود دارد، نوشته شده است:
اهمیت این مقاله در آن است که تابهحال در پژوهش کمتر به اثر سبک روابط خانوادگی (مانند نحوه تعارض بروز هیجانی و انسجام خانوادگی) در مورد رفتارهای آسیبرسان با نقش عوامل منفی و دشواری در تنظیم هیجانی پرداخته شده است.
موضوعی که نویسنده سطور فوق باید بداند اینکه نمیتواند با شاخصهای برازش این مدل را تأیید کرد. دلیل اینکه در این همه پژوهشهای انجامشده به این روابط اشارهای نشده است به دلیل نادرستی این شیوه تحلیل است که نمیتواند این جهات علی را با جمعآوری دادههای میدانی و کاربست آن در مدل معادلات ساختاری مورد تأیید قرار داد. درواقع انبوهی از این نوع مقالهها که رابطه دومتغیره از طریق یک میانجی را بررسی میکند در ادبیات پژوهشی وجود دارد که صرفاً برای توجیه آن، دوبهدو، به رابطههای متغیرهای دخیل در آن از طریق زبان پرداختهاند. توجیهات معمولاً با کمی چرخش در زبان در جهت عکس هم امکانپذیر است. از رابطه متقارن دوطرفه نمیتوان به روابط سه متغیره نامتقارن رسید زیرا معادله ساختاری حافظ تقارنی است که بین متغیرها وجود دارد.
4- مدل ذهنی نادرست از کامپیوتر بهمثابه ماشین فرضیهساز
کداک زمانی در تبلیغات خود این شعار را باب کرد: «فشار دادن دکمه از شما، مابقی با ما » (YPB, WDR) این تقریباً کاری است که در تحلیل رگرسیون چندگانه صورت میگیرد. پرس بری این دو جمله را با حروف اختصاری WDR و YPB برجسته ساخته است و مراد آن کارهای آماری است که در آن کاربر فقط باید دکمهای را فشار دهد. این ایده بسیار مهم را در مورد چهارم بهتفصیل موردبحث قرار دادهایم و در اینجا به این تصور غلط که میتوان از ماشین انتظار تفکر و فرضیهسازی داشت هم پرداختهایم.تحلیل رگرسیون چندگانه را که سادهترین شکل پیشبینی متغیر y از n متغیر پیشبینی کننده است میتوان یک ماشین نادرست از مدل ذهنی پژوهشگرانی دانست که بهصورت دلخواه این متغیرها را برای تعریف معادلهای ساده از رگرسیون پیشنهاد میکند.
متغیرهای میتوانند هر متغیری باشند که از طریق پیشینه با y مرتبط شدهاند. ممکن است متغیرهای از طریق یک متغیر با y همبستگی خیالی پدید آورند. معمولاً از طریق این متغیرهای سوم همواره رابطهای قابلتصور است. بدترین وضعیت برای پژوهشهای رابطهای آن است که هیچ رابطهای از قبل اندیشیده شده و مبتنی بر پیشینه نظری نباشد. همچنین این متغیرها نباید متغیرهایی باشند که با وجود تناقض با یکدیگر همزمان در فرد وجود داشته باشند؛ بنابراین تعریف آن در وجود یک فرد موهومی باشد. مثلاً اگر فردی دارای دلبستگی ایمن باشد، نمیتواند همزمان سبک دلبستگی ناایمن هم داشته باشد. بهعبارتدیگر، نقطه برشی وجود دارد که اگر نمره فرد زیر آن نقطه باشد، سبک دلبستگی ناایمن دارد و اگر نمرهاش بالای آن نقطه باشد، سبک دلبستگی او را ایمن باید محسوب کرد. این متفاوت از ویژگیهای شخصیتی از قبیل برونگرایی یا درونگرایی است که افراد روی یک پیوستار قرار میگیرند و میتوانند هراندازهای در این پیوستار کسب کنند.
باید توجه داشت که رگرسیون چندگانه دارای فرضیه نیست زیرا باید ترتیب متغیرها و اصولاً انتخاب آنها توسط پیشینه معلوم شود؛ درحالیکه پژوهشگر از قبل نمیتواند چنین ترتیبی را مقرر کند بلکه این ماشین است که ترتیب را بر مبنای WDR و YPB مشخص میکند. بهاینترتیب اندیشیدن به سهولت فشردن یک دکمه تبدیل میشود! اگر متغیرها بر اساس پیشینه یا نظریه در مدل آورده شده باشند، از رگرسیون توانمندتری باید استفاده کرد که رگرسیون سلسهمراتبی نامیده میشود. رگرسیونهای چندگانه و سلسله مراتبی به ترتیب مثالهایی از تحلیل اکتشافی و تحلیل تأییدی است. تفاوت عمده آنها این است که تحلیلهای اکتشافی دارای فرضیه نبوده و بنابراین نمیتوان آنها را به جز یک جستجوی تیری در تاریکی چیز دیگری دانست. اصطلاحی که گال، بورگ و گال (1996) برای این نوع جستجو انتخاب کردهاند.
در مدل ذهنی نادرستی که پژوهشهای زیادی را در ایران تولید کرده و معمولاً در عنوان این پژوهشها رابطه ساده و چندگانه دیده میشود، فرضیه اصلی این است که ترکیبی از متغیرهای x2 متغیر y را پیشبینی میکند. من این جملهها را فرضیهنما مینامم زیرا هیچگاه این فرضیهها باطل نمیشوند و همواره تأیید میشوند؛ تأییدی که البته واقعی نیست زیرا یک فرضیه پژوهشی بنا بر ملاکهای فلسفه علم باید ابطالپذیر باشد، درصورتیکه این جملهها ابطالپذیر نبوده و شبیه گزارههای فلسفی هستند. کامپیوتر از دو تابع حداقل مجذورات و بیشینه احتمالی برای ترتیب این متغیرها سود میجوید و ظاهراً برای این مدل ذهنی پاسخی جادویی فراهم میآورد: فرضیههای که همواره تأیید میشوند. باید توجه داشت که رگرسیونهای چندگانه نوعی جستجوی خوابگردانه است. درجایی که هیچ رابطه مبتنی بر فرضیه نمیتوان بین متغیرها ترسیم کرد و بسته به ماهیت پژوهش میتوان از هر یک از شکلهای پیشرو ، پسرو یا گامبهگام استفاده کرد. بعد از آن میتوان این جستجوی خوابگردانه را با طرحهای پژوهشی قوی از قبیل طرحهای طولی یا آزمایشی دنبال کرد و بهصورت مستقل نمیتوان آن را پژوهش نامید. بعداً و در آن مرحله میتوان فرضیه برای پژوهش نوشت.
خوشبختانه استفاده از آنها در مقالههای رفاه اجتماعی فقط محدود به یک مقاله است. نامنی و همکاران (2016) تعهد زناشویی را بر اساس سبکهای عشقورزی پیشبینی کردهاند که این سبکهای عشقورزی شامل رمانتیک، جنونآمیز و وفادارانه است که افراد در زندگی زناشویی یکی از این شکلهای عشقورزی را دارند که نمیتوان بین آنها رابطه نموی برقرار کرد و حتی اگر چنین باشد نمیتوان برای آن فرضیهای ساخت. اینکه عشق جنونآمیز به عشق رومانتیک چیزی میافزاید درواقع بیمعناست. این دو عشق در وجود فرد واحدی نیستند که دومی بر اولی افزوده شود درحالیکه معادله رگرسیون مبتنی بر این افزونگی است. در مقاله دیگری هم (نامنی و قربانی، 2018) این روش این بار در مدل معادلات ساختاری دنبال شده است.
در مقاله، خود آنها راجع به Red CV ادعایی کردند که درست نیست و به معنی باوری است که بسیاری از محققان علوم انسانی نسبت به تواناییهای مدل معادلات ساختاری دارند، حتی گاهی آن را مدل علی هم نامیدهاند. در ص 166 ادعا شده است:
آزمون کیفیت مدل ساختاری را بیان میکند به این معنی که ... آیا متغیرهای مناسبی در قالب مدل ساختاری قرارگرفتهاند یا خیر. آیا فرضیات پژوهشی مناسب انتخاب شده یا خیر (منظور نویسنده آزمون استون گایزر است). با توجه به محدودیت فضا در مدل PLS دو شاخص در بخش ارزیابی، اشتراک com و افزونگی Red است که به ترتیب مقادیر آن مجذور همبستگی
و میانگین واریانس مجموعه متغیرهای آشکار است.در آزمون استون گایزر که در آن بخشی از ماتریس دادهها به کمک روش جک نایف برای برآورد پارامترها حذف شده و از طریق پارامترهای برآورده شده بخش حذفشده برآورد میشود (شبیه روش اعتباریابی متقاطع یا روشهای مشابه دیگر در باز نمونهگیری) در این حالت اگر مقدار Red CVv (که هم نامیده میشود) منفی باشد برآورد بلوکهای ارزیابی شده ضعیف است. انتخاب متغیرها و درستی فرضیهها کاملاً در فضای مفهومی پژوهش ایجاد شده و هیچ ربطی به محاسبات فوق ندارد. کتاب هنسلر و همکاران (2009) که در منابع نامنی و قربانی (2018) به آن اشاره نشده، اما به آن ارجاع داده شده است، درواقع نویسندگان رانیارتز، هنیلین و هینسلر (2009) است که کاربردهای PLS در بازاریابی شرح داده شده است و مقالات بسیار تخصصیتر را میتوان (حتی در زبان فارسی) راجع به PLS یافت.
جان سرل، فیلسوف مشهور، استعارهای ساخته است که مرد چینی نام دارد و دستورالعملهایی را به فردی که زبان چینی نمیداند ارائه میدهد و آن فرد باید بدون دانستن زبان چینی و فقط در سطح صورت از آن دستورالعملها نتیجهگیری کند، درحالیکه آن فرد برای فهم درست دستورالعملها نخست باید زبان چینی را بفهمد. موقعیت کاربرد نرمافزارها بهخصوص مدل معادلات ساختاری بسیار شبیه دستورالعملهای مرد چینی است: پژوهشگرانی که آن را به کار میبرند، نخست باید منطق آن را بدانند.
5- استفاده از تحلیل میانجی به جای تحلیل تعدیلی
اصغریکماء و همکاران (2021) در توجیه رابطه میانجی بین متغیرهای پژوهش خود به پژوهش خجستهمهر اشاره کردهاند که در آن رفتارهای فداکارانه همسر به سبکهای دلبستگی و کیفیت زندگی میانجیست. درواقع پژوهشگر حتی اگر درست استدلال کرده باشد متغیر میانجی رفتارهای فداکارانه همسر بین دو متغیر x و y در پژوهش خجستهمهر را دلیلی بر میانجی بودن آن بین دو متغیر دیگر در پژوهش خود z و d دانسته است؛ کاری که بهوضوح نادرست است. انگار اگر متغیری در جایی متغیر میانجی بود، در هر پژوهش دیگر و بین هر دو متغیر دیگر هم میانجی است! متأسفانه این نوع اشارهها در مقالات حاوی تحلیل میانجی در ایران کم نیست. اما جایی دیگر از مقاله با اشاره به پژوهش سطانزاده (2012) استدلال شده است که دریافت پاسخهای همدلانه از سوی همسر بهمثابه یک ضربهگیر در برابر اثرات منفی افسردگی و سوءمصرف مواد عمل میکند. هرکسی که با متون روانشناختی اندک آشنایی داشته باشد میداند که متغیرهای ضربهگیر همواره به لحاظ آماری متغیر تعدیلگر هستند. درواقع در اینجا پژوهشگر تحلیل میانجی را به جای تحلیل تعدیلی بکار برده است.برای اینکه ضعف پیشینه درنتیجهگیری میانجی در تحقیق را نشان دهم به یک پژوهش دیگر اشاره میکنم که هم در جهان انگلیسیزبان (دامبران و رایکار 2011) و هم در جهان فرانسه زبان (دامبران، 2011 و دامبران و رایکار 2012) بهخوبی پیشینه آن شناخته شده است و بنابراین نظریهای استوار در مورد آن وجود دارد و بسیار متفاوت از استدلالهای مبتنی بر چند برداشت سطحی است. این پژوهش در مورد نقش میانجی پایداری هیجانی (با N در NEO) بین دو متغیر فداکاری (ناخودی) و شادی اصیل و مستمر است. نظریه آنها مبتنی بر این فرضیه است که شادی در افراد خود مرکز بین ناپایدار است. درحالیکه شادی در افراد فداکار (ناخود) از پایداری هیجانی برخوردار است. او برای انجام تحلیل میانجی نخست با تحلیل عاملی اکتشافی و تأییدی مجزابودن دو سازه ناخودی (فداکاری) و خودمرکزبینی را نشان میدهد و سپس همبستههای آنها (شادی اصیل و خودمتعالی برای ناخودی و شادی ناپایدار برای خودمرکزبینی) را بر اساس نظریههای متعدد در طول ده سال گذشته و دادههای تجربی مطالعه اول خود، وارد مدل تحلیل میانجی میکند. اصغری و همکاران که به حیطه خاص سازه ناخودی در رفتار همسر پرداختهاند به نظریهپرداز آن و مجموعه وسیع کارهای او هیچ اشارهای نمیکنند. آنها رابطهای را بر مبنای پیشینه در مقاله خود آن هم فقط در یک سطر به نقل از استنفنسون و همکاران (2014) به نقل از عباس و رستمی 2020 میآورند که نقش ضربهگیر فداکاری همسر است.
نمودار (3)
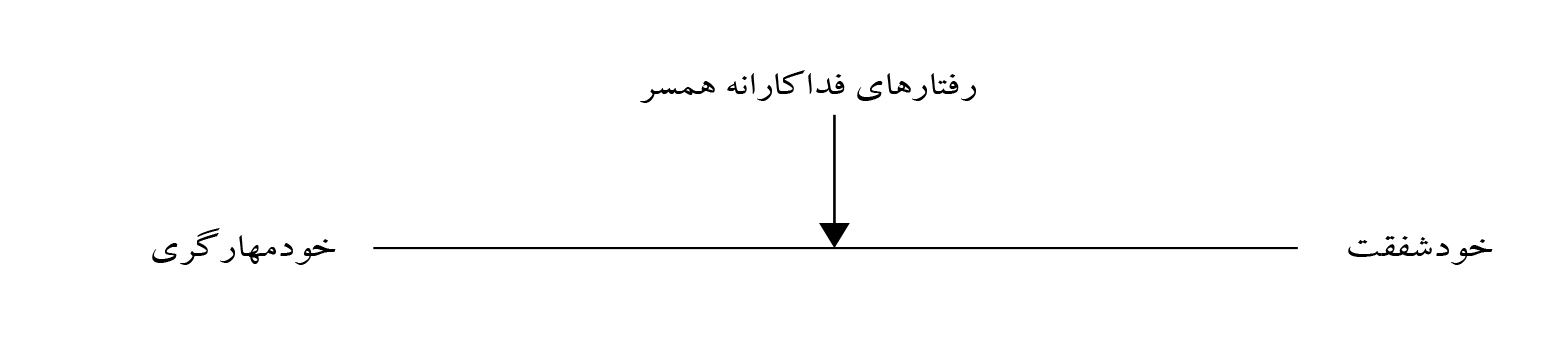
این مدل با توجه به پیشینه و درک عادی غلط است و به نظر میرسد که خود مهارگری نقش تعدیلگر دارد، اما در این مطالعه بهعنوان متغیر میانجی در نظر گرفته شده است. اینکه متغیرهای ضربهگیر همواره متغیر تعدیلگر در نظر گرفته میشوند نیاز به بحث مفصلی دارد و مقاله مستقلی میطلبد. اما سؤال این است که چرا پژوهشگران ترجیح میدهند به آن نقش میانجی بدهند. یک دلیل ساده این است که ارائه آن با مدل معادلات ساختاری راحتتر است. در ایران فقط یک مقاله در مورد نقش تعدیلگر با استفاده از مدل معادلات ساختاری گزارش شده که در بخش سیزدهم همین مقاله به آن اشاره شده است.
مورد دوم مقاله ایرانی و همکاران (2018) است که در آن نیز تحلیل میانجی به جای تحلیل تعدیلی بکار رفته است. خطاهای مقاله از همان آغاز و در عنوان مشخص است مسکن مهر و مسکن اجتماعی دو پدیده کاملاً مختلف و با اهداف متفاوت هستند. سؤال پژوهش این است که سیاستگذاری و اجرای مسکن اجتماعی با چه آسیبهایی روبروست و پیامدهای آن در بازتولید نابرابری طبقاتی و گرایش به انحرافات اجتماعی در محیط مسکونی واقع در مسکن مهر تبریز سهند چگونه است؟ نویسنده از همان آغاز در ذهن خویش هیچ اشارهای به مسکن مهر نکرده و به جای آن به مطالعات مسکن اجتماعی در پیشینه نظری اشاره کرده و در بخش پیشینه تجربی غیر از اشاره به نام پژوهشها (داخلی و خارجی) هیچ چهارچوب پنداشتی در معرض بحث قرار نگرفته است و ناگهان، بدون هیچ مبنای منطقی مدل زیر پیشنهاد میشود (ص 154) این مدل یکی از سه مدل همارز (همرس ، مخدوشگر و میانجی ) است یعنی مدل مخدوشگر است که بهوضوح نادرست است.
نمودار (4)
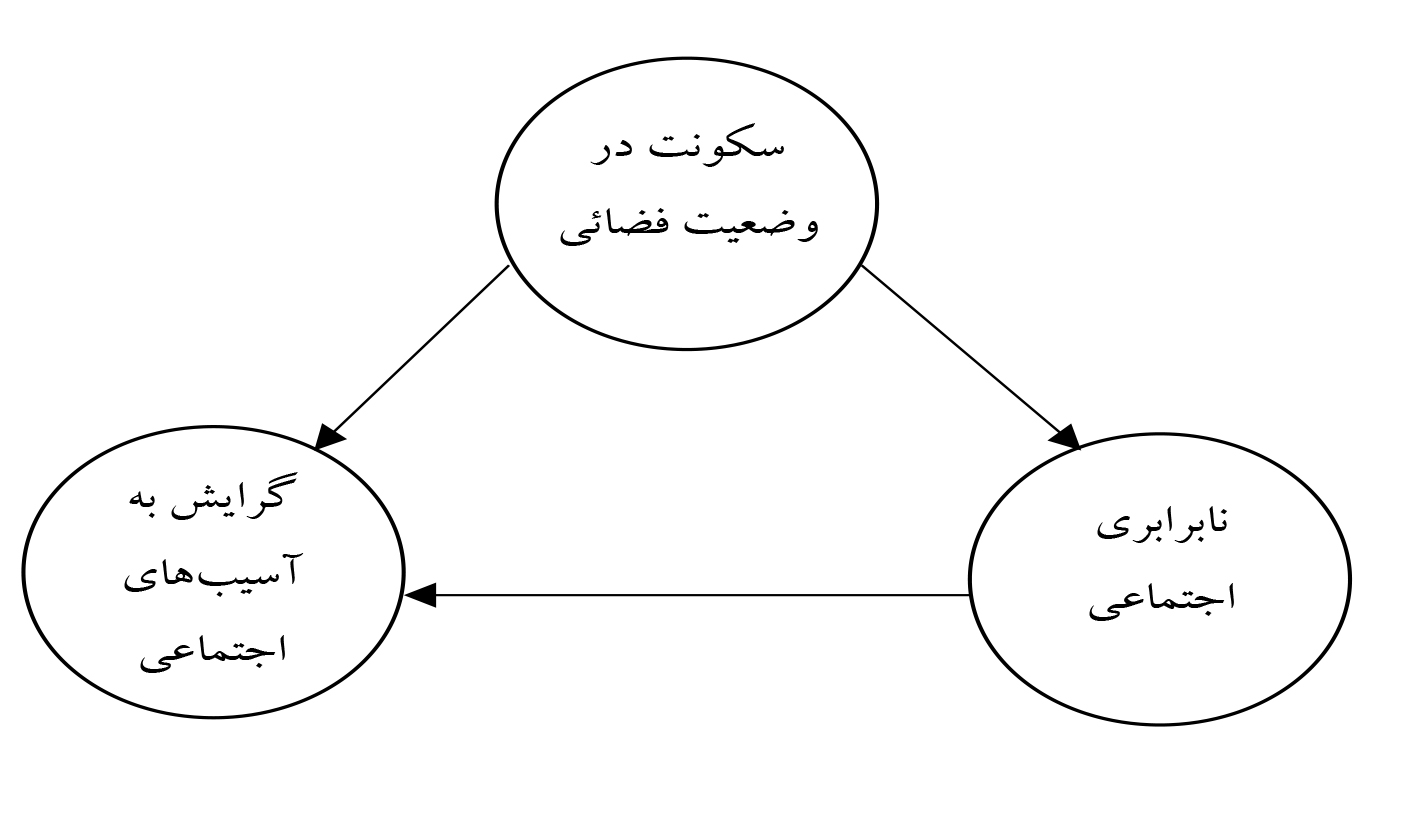
مدل صحیح بر مبنای عقل سلیم مدل میانجی است به شکل زیر است.
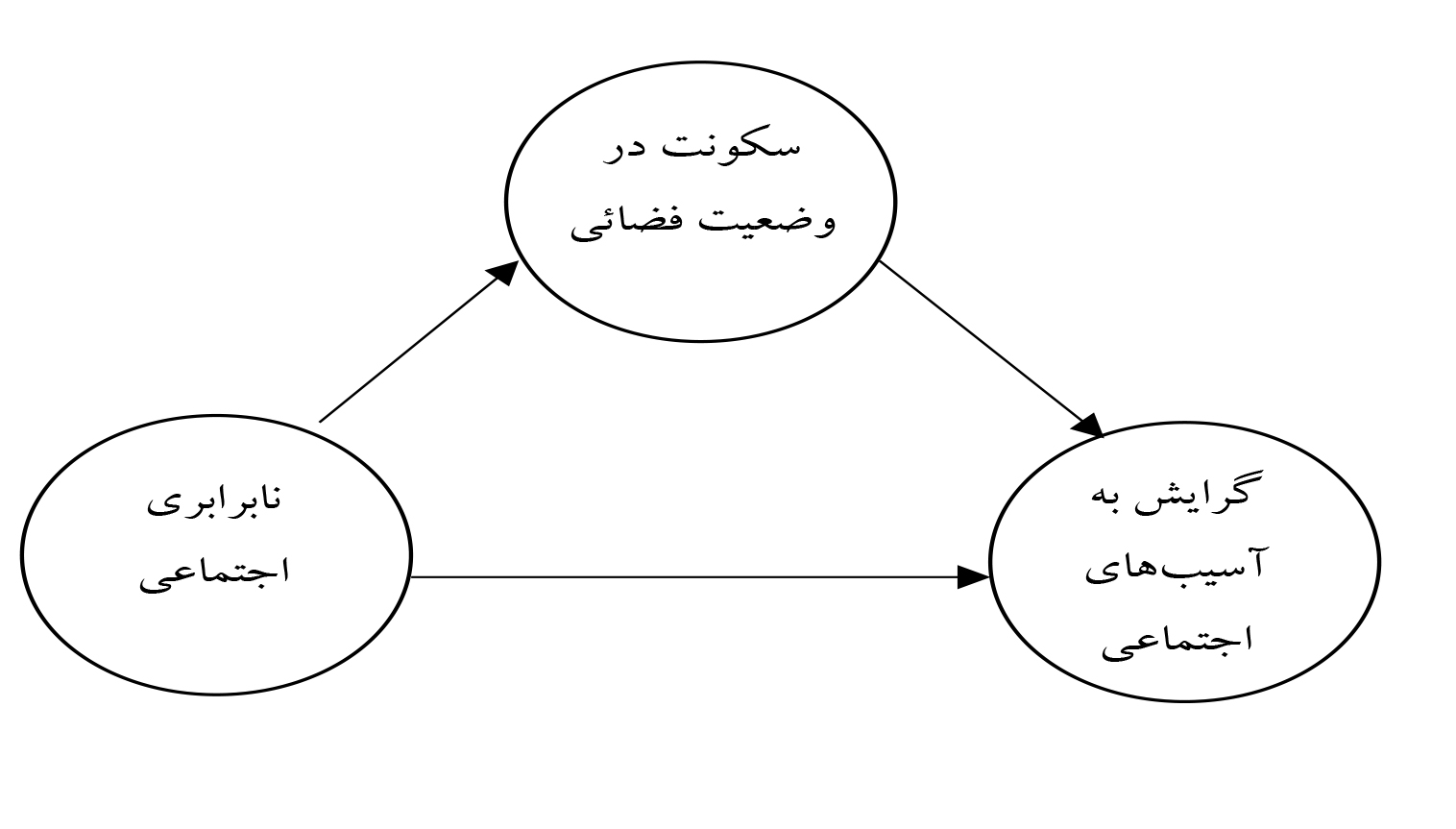
در همه جای جهان افراد ثروتمند در وضعیتهای فضایی خاصی ساکن میشوند که بر تمایز آنها از دیگران تأکید میکند و افراد فقیر نیز در وضعیتهای محلههای فقیرنشین سکنا میگزیند. این نابرابری اجتماعی است که سکونت در وضعیت فضایی را ایجاب میکند و نه اینکه سکونت در آن فضا مقدم بر نابرابری اجتماعی است. از زمان مارکس این ایده تثبیت شده است که نابرابری اجتماعی زیربنا و علت و منشأ روبناهایی از قبیل سکونت در وضعیت فضایی و گرایش به آسیبهای اجتماعی است. نویسندگان به نادرست یک مدل میانجی را به شکل مدل مخدوشگر ترسیم کردهاند. هرچند شاخصهای برازش هیچ تفاوتی با یکدیگر ندارد و به همین دلیل آنها را مدلهای همارز میگویند. تصور نویسندگان آن است که مدلی را تأیید کردهاند که ترسیم کردهاند ولی مدل درست، مدل همارز آن یعنی مدل میانجی است.
نویسندگان در مدل فوق، بدون هیچ دلیلی وضعیت سکونت در مسکن مهر را بهعنوان وضعیتی تلقی کردهاند که محرومیت اجتماعی را برای ساکنانش به لحاظ طرد و تفکیک قشری و بازتولید نابرابری ایجاد کرده است (ص 151). این جمله علیرغم طنین لوفوری که دارد، کاملاً از اندیشههای او خالی است. درواقع جهت فلش از نابرابری اجتماعی سکونت در وضعیت فضایی مسکن مهر با منطق هماهنگتر است. مثلاً فقر که عامل شناختهشدهای برای افزایش گرایش به آسیبهای اجتماعی است، در زاغهها و حاشیهها بهتر محل بروز دارد یا سکونت در وضعیت فضایی مسکن مهر؟ برای پاسخ به این سؤال بهتر است گروه پایه مقایسه (حاشیهنشینها) وجود داشته باشد و بدون آن هیچ نتیجهگیری درست نیست.
یکی از خطاهای پایهای این تحقیق آن است که باید از مدلسازی خطی سلسله مراتبی (HLM) استفاده میشد. در آینده در مجله رفاه اجتماعی مقالهای خواهم نوشت و در آن روش تحلیل این دادهها را نشان خواهم داد.
نویسندگان به جای گروه پایه، سکونت را بهصورت یک متغیر پیوسته درآوردهاند و بنابراین تحلیل آنها یک موضوع بسیار ساده و از پیشدانستهای است: فقر سبب میشود که انحراف از هنجارهای اجتماعی صورت پذیرد.
در این حالت محل سکونت بهصورت متغیر تعدیلگر درآمده و رابطه طبیعی نابرابری اجتماعی گرایش به آسیبهای اجتماعی تحت تأثیر آن قرار میگیرد. برخلاف تصور نویسندگان مقاله، شاخص افزونگی (Redcv) Structural model quali index نمیتواند تعیین کند که آیا متغیرهای مناسبی در قالب مدل ساختاری قرار گرفتهاند یا خیر. درواقع شاخصهای تأیید که مدل را تأیید میکنند هر نوع تغییر جهت فلشها را هم تأیید میکنند و مجموعه این بحث در ادبیات آماری به مدلهای همارز شهرت دارد. (ازجمله مثل مدل میانجی با متغیر مخدوشکننده همارز است که در بخش چهارم به آن پرداخته شد). اگر این تحلیل میانجی باشد، چهارچوب نظری درستی ندارد، زیرا سکونت در مسکن مهر تحت تأثیر نابرابری اجتماعی است که به نظر نویسنده مقاله حاضر و خلاف نظر نویسندگان مقاله قابلقبول است. ولی در مورد متغیر سوم یعنی گرایش به آسیبهای اجتماعی، درست به نظر نمیرسد که گرایش به آسیب اجتماعی از سکونت در مسکن مهر ناشی شود. این ادعای بزرگی است که خلاف جهت بین دو متغیر دیگر نیاز به تغییر طرح پژوهش دارد. یعنی در یک مطالعه طولی باید بررسی شود که آیا سکونت در وضعیت فضایی مسکن مهر است که گرایش به آسیبهای اجتماعی را میسازد یا برعکس این گرایش به آسیبهای اجتماعی است که سکونت در وضعیت فضایی مسکن مهر را پدید میآورد و هیچ پیشینهای در این زمینه وجود ندارد. هرچند این یک متغیر طبقهای است. اما پژوهشگران به دلیل تمایل به کاربرد PLS از آن یک متغیر پیوسته ساختهاند (ص 156). پژوهشگران در توجیه این کار خود امکان سنجش متغیرها در سطح فاصلهای و درنتیجه امکان بهکارگیری آزمونهای پیشرفته آماری را میآورند... درواقع یا پیوسته کردن سکونت، سکونت در وضعیت مسکن مهر به معنی طبقه اجتماعی پایین (فقیر) خواهد بود. بنابراین فرضیه ساخته شده توسط پژوهشگران امری بدیهی است یعنی فقر، آسیب اجتماعی و نابرابری اجتماعی ایجاد میکند. اگر سکونت در وضعیت مسکن مهر با سطح پایه پایینتر خود مقایسه میشد (مثلاً زندگی در زاغه) در آن صورت نتایج کاملاً متفاوت بود. کاربرد آزمون t (سوبل) نادرست بوده و باید همانطور که در همه مقالات تحلیل میانجی نوشته شده از توزیعهای تجربی (بوت استراپ یا جک نایف) استفاده شود. مطالب بحث و نتیجهگیری حاوی خطاهای پرشماری است. فقط به یکی از آنها اشاره میکنم نویسندگان مدعی شدهاند که نابرابری امنیت اجتماعی بر گرایش به آسیبهای اجتماعی بیش از غیر ساکنان مؤثر بوده است. آزمون آن فقط از طریق تحلیلهای موسوم به میانجی تعدیلی (عریضی،1387) امکانپذیر است که در پژوهش حاضر این تحلیل انجام نشده است؛ الگویی که من به جای الگوی فوق منطقی میدانم. ادعاهایی که در مورد PLS شده، غیرواقعی است. ازجمله این ادعا که اجرای همزمان مدلسازی اکتشافی و تأییدی از ویژگیهای Smart PLS است. این ادعاها درباره نرمافزارها و ماشین را در بخش چهارم همین مقاله به تفضیل موردبحث قرار دادم. بسیاری از نرمافزارها میتوانند مدلسازی اکتشافی و تأییدی را بهطور همزمان اجرا کنند. این پژوهشگر است که تشخیص میدهد کدام دادهها باید در معرض تحلیل اکتشافی و کدام دادهها در معرض تحلیل تأییدی قرار گیرند. مرحله اول در مثلاً تحلیل عاملی، تحلیل عاملی اکتشافی EFA و در مرحله دوم و روی دادههای مجزا تحلیل عاملی تأییدی CFA انجام میگیرد. برای مطالعه تحلیل تأییدی و اکتشافی و تفاوت آن دو با یکدیگر و اینکه دادههای این دو نوع تحلیل متفاوتند یک مقاله خوب عریضی (2007) به فارسی وجود دارد. درواقع دو خانواده از روشها در مدلسازی معادلات ساختاری وجود دارد که یک روش با مبنای عاملی (رویکرد تأییدی) و دیگری با مبنای مؤلفهای (رویکرد اکتشافی) است. که در اولی متغیرهای مکنون معادل عامل مشترک و در دومی مجموع موزون متغیرهای آشکار است.
این الگوست که با عقل سلیم و پیشینه پژوهشها بیشتر هماهنگ است.
نمودار (5) مدل درست در مقاله سعید ایرانی، منصور حقیقتیان و اصغر محمدی

این تحلیل، یک تحلیل تعدیلی است که در آن سکونت در مسکن مهر بر رابطه تأثیر میگذارد (و نه آن که مانند تحلیل میانجی آن را ایجاد کند). ممکن است نویسندگان تصور کنند مدل آنها تأیید شده است و امکان ندارد که با دادههای آنها این امر میسر باشد.
گاهی پژوهشگران مدلهای میانجی و تعدیلی را خلط کردهاند، مثلاً: در پژوهش محمود علیلو و همکاران (2014)، هم عقل سلیم و هم پیشینه نظری، این مدل را تأیید میکند.
نمودار (6) مدل صحیح رابطه متغیرها در پژوهش علیلو و همکاران
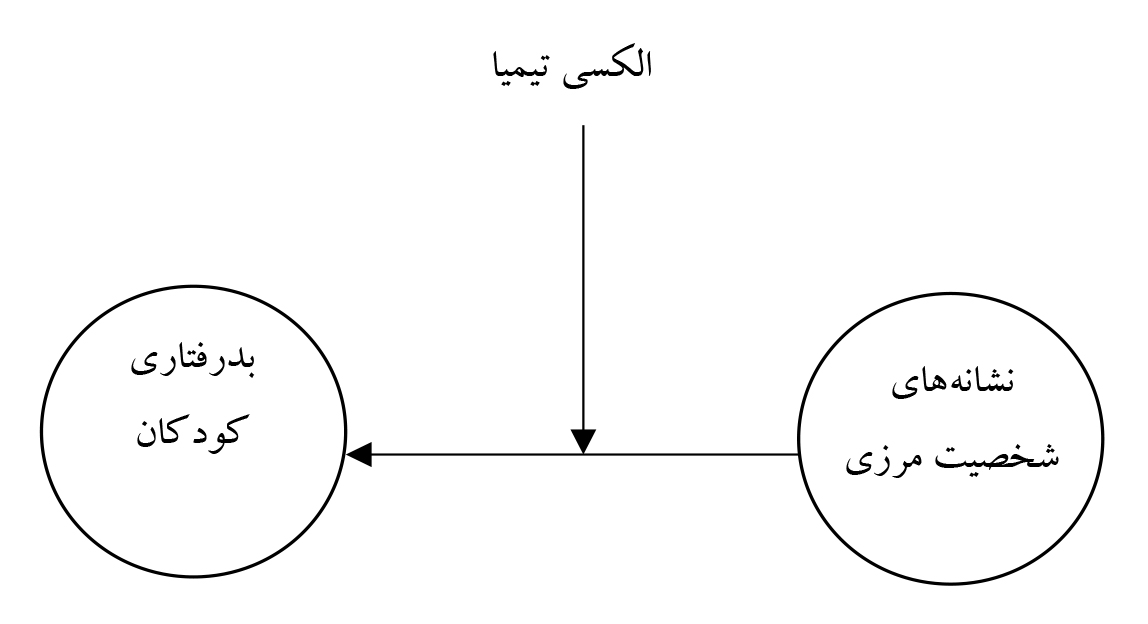
آنها اما فقط و فقط به دلیل ترجمه غلط در پیشینه نظری و شباهت صوری دو واژه Moderating و Mediating تصور کردهاند که الکسی تیمیا نقش میانجی دارد. آنها به نقل از گرانر و همکاران (2011) به این نقش میانجی اشاره کردهاند و دادهها را به دلیل ترجمه نادرست با تحلیل میانجی تأیید کردهاند. درحالیکه در ابتدا باید تحلیلهای تعدیلی صورت گیرد تا تحلیل میانجی انجام شود. باز هم تأیید مدل با شاخصهای برازش به معنی درستی آن نیست (به مورد سوم در همین مقاله نگاه کنید). گاهی افراد مدل نادرستی را برای پژوهش خود استفاده کردند. مثلاً پاکنهاد و همکاران (2020) در صفحات 60 و 67 متغیر کنش یاریگرانه را متغیر تعدیلی بین شبکههای اجتماعی مجازی و قابلیت یادگیری سازمانی معرفی کرده است؛ درصورتیکه هم آمارهها و هم نمودارها در مقاله خود او این متغیر میانجی است. جالب است که بدون توجیه مدل او از شاخصهای تأییدی برای تأیید مدل استفاده کرده است. قبلاً او باید برای تأیید ابراز خود در تحلیل عاملی از این شاخصها استفاده میکرد. یعنی جایی که نباید از آنها استفاده کند آنها را به کار برده است (در تأیید مدل نظری) و جایی که باید از آنها استفاده میکرد آنها را به کار نبرده است (در تأیید ساختار عاملی ابزارها).
استفاده از آزمون سوبل هم نادرست است که جای دیگر به آن اشاره کردهام. نیکوگفتار (2014) فکر میکند متغیر میانجی و تعدیلی اصولاً یکی است (صفحه 123). او آنها را به صورتی کامل مترادف به کار میبرد. ناآشنایی با تعاریف متغیرها در مجله رفاه اجتماعی زیاد به چشم میخورد که بارزترین آن بین متغیر میانجی و تعدیلی است.
در کل سه متغیر میانجی در محله رفاه اجتماعی بررسی شده است. علاوه بر مقاله فوق دو مقاله پاکنهاد و همکاران(2020) و گودرزی و همکاران (2021) نیز وجود دارد. در هیچ یک از این دو مقاله نقش میانجی در پیشینه توجیه نشده است. در مقاله اول اصولاً پژوهشگران گاهی متغیر کنش یاریگرانه را میانجی (در عنوان) و گاهی تعدیلی (مثلاً صفحه 60) نامیدهاند که نشان میدهد پژوهشگران تفاوتی بین آنها قائل نیستند. درواقع هیچکدام از دو پژوهش ادریسی و رحمان خلیلی (2012) و ابوالحسنی رنجبر (2012) که برای توجیه تأثیر شبکههای مجازی بر کنشهای یاریگرانه آمدهاند ربطی به آن ندارد. به نظر میرسد که نقش تعدیلی بر نقش میانجی برای کنشهای یادگیرانه منطقیتر به نظر میرسد و هیچ توجیهی برای این مدل وجود ندارد و کاملاً غلط است. جدول (1) که تحت عنوان تحلیل عاملی تأییدی آمده است بارهای عاملی آمده که نادرست است و باید شاخصهای برازش گزارش میشد. در مقاله دوم نیکوگفتار (2014) مجدداً تحلیل میانجی و تعدیلی را یکی گرفته است (ص 123) که خطا است.
6- استدلال به شیوه هامپتی دامپتی
در مورد تحلیل تعدیلی و میانجی، گزی و محمدیآریا (2015) به شیوهای بینظم به رابطه سرمایه اجتماعی و فرهنگ سازمانی پرداختهاند. بحث آنها در موارد پیشینه زاید و بیربط است. در جدول (1) که خلاصه پژوهشهاست فقط سه پژوهش راب و زامسکی (2001)، بوگلزدیک (2003) و طاهره فیضی (1387) به موضوع ظاهراً مرتبط است و بقیه کاملاً بیارتباط است. به نظر میرسد پژوهشگران برای مستند ساختن مطالب خود مطالبی را به پژوهشهای دیگران نسبت میدهند تا زبان خصوصی خود را مستدل کنند. مثلاً پژوهش راب و زمسکی (2000) را چنین شرح میدهند که مطلوبیت همکاری به میزان همکاری دیگران در گذشته و شدت انگیزش وابسته است امری که واضح است و چندان ربطی به فرهنگ سازمانی ندارد اما چگونه به سرمایه اجتماعی موضوع پیوند میخورد؟ همکاری نیروی کار که تا اینجا سعی میشود به آن نقش فرهنگ سازمانی (مشارکتی) داده شود (صفحه 142) در سطر بعد به معنای سرمایه اجتماعی است. نویسندگان ادامه میدهند همکاری نیروی کار (سرمایه اجتماعی) فرآیند پویایی را دنبال میکند که در آن شدت انگیزش بهعنوان متغیر کنترلکننده عمل میکند. لابد اگر رابطه این متغیرها با انرژی رابطهای مطرح میشد نویسندگان در جمله بعد مینوشتند میزان همکاری مطلوبیت (انرژی رابطهای) فرایندی اثربخش است که تابع سازوکارهای کنترلی ازجمله شدت انگیزه است.
در آمار ارائهشده پژوهشگران همچنان فرضیههای ساختگی را با آماری نادرست دنبال میکنند، آنها مدعیاند که تحلیل دادهها متناسب با سطح سنجش متغیرها صورت گرفته است. امری که حرف آن را میزنند اما اجرا نکردهاند زیرا از تحلیل چند سطحی که توصیه یکی از منابع آنهاست استفاده نکردهاند. آنها در جدول 7 (صفحه 155) مجموعهای از رابطههای دو متغیری بین دانشگاه، جنسیت، وضعیت تأهل، محل سکونت، وضعیت بومی و وضعیت استخدامی را تحت عنوان متغیرهای تعدیلی آوردهاند اما در هر مورد دوگانهای (مثلاً مرد و زن) ساخته و رابطههای مستقل آن را با این متغیرها گزارش دادهاند. مثلاً در مورد جنسیت ضرایب همبستگی 368/ 0 (مرد) و 575/ 0 (زن) را به دست آوردهاند؛ اما معلوم نیست که اینها چه تفاوتی دارند. اگر به z فیشر تبدیل و ضرایب همبستگی مقایسه میشوند باز هم به معنی نقش تعدیلی نیست. در مورد اثر غیرمستقیم (میانجی) هم نتایج رها شده و معنیداری آن با بوت استراپ بررسی نشده است (صفحه 157).
7- عدم توجه به محدودیت دامنه و استنتاجِ نبودِ رابطه بین متغیرهایی که بهوضوح دارای ارتباط هستند.
در مقاله دیگری که حقیقیان و جعفری (2013) در مورد سرمایه اجتماعی و بهداشت روانی در میان حاشیهنشینان نوشتهاند نکته عجیبی که وجود دارد این است که رابطه پایگاه اجتماعی ـ اقتصادی تنها 02/ 0 بهداشت روانی را تبیین میکند و 98% آن مربوط به عوامل دیگر است. این با پیشینه پژوهشها در تعارض است. میدانیم که فقر یکی از عوامل عمده در از دست دادن سلامت روانی است. دلیل این خطا مسئلهای است که آن را محدودیت دامنه در آمار مینامند: نمونه از میان حاشیهنشینان گرفته شده است و بنابراین دامنه نمونه بسیار محدود شده است. هنگامی میتوان ضریب تعیین واقعی را به دست آورد که نمونه در کل جامعه گرفته شود و نه در بخش محدودی از آن. میتوان مثالهای جالبی در این مورد ارائه کرد. با وجود عقل سلیم رابطه قد بازیکنان بسکتبال با تعداد گلهای به ثمر رسیدن آنها رابطه معناداری ندارد. زیرا همه آنها دارای قدی نزدیک به هم هستند و با یک پرش هرچند کوتاه آن اختلاف قد پوشیده میشود. نویسندگان در همین مقاله خطاهای متعدد دیگر نیز مرتکب شدهاند. مثلاً در حالی ضریب تعیین 11% است که در مقاله خود آنها گزارش شده است. آنها بعداً با جمع زدن ضرایب، برای ضریب تعیین مقدار 5/13% را به دست آوردهاند. این اختلاف 5/2% به دلیل آن است که نمیتوان ضرایب همبستگی مجزا را در رگرسیون گامبهگام مجذور کرد و ضریب تعیین نهایی را به دست آورد زیرا متغیرهای وابسته با متغیر ملاک همپوشانی در همبستگی دارند.
8- استفادههای نادرست از شیوههای تحلیل آماری
مهمترین اشکال استفاده نادرست از شاخصهای برازش برای تأیید مدلهای است که این شاخصها هنگامیکه آن مدلها ویژگی علی موردنظر (همرس، میانجی یا مخدوشکننده) را نداشته باشد به تصور نویسنده مقاله به تأیید مدل مدنظر آن میپردازد. همین اشتباه ساده حجم وسیعی از پژوهشها را پدید آورده که همگی نادرست است. عریضی با بررسی 200 پژوهش میانجی رشتههای مختلف در ایران دریافت که رابطه علی موردنظر فقط در سه مقاله بهدرستی مورداشاره قرار گرفته است (عریضی، 2020). اشکال دیگر استفاده از آزمون سوبل در تحلیل میانجی است که بیش از چهار دهه از رد آن در تحلیلهای میانجی گذشته است و متأسفانه در پژوهشهای داخلی همچنان به کار میرود؛ مثال آن در پژوهش پاکنهاد و همکاران(2020) است که برای تأیید تحلیل میانجی از آزمون سوبل برای معنیداری اثر غیرمستقیم استفاده شده است. در این جا باید به یک نظریه مهم در آمار ریاضی اشاره کنیم: هنگامیکه دو توزیع نرمال باشند مجموع آن دو توزیع نیز نرمال است اما حاصلضرب آنها مشخص نیست که نرمال باشد. ازآنجاکه اثر غیرمستقیم ضرب دو ضریب رگرسیون است، مشخص است که نمیتوان از آزمون سوبل که یک توزیع متقارن حول اندازه شاخص در نمونه است استفاده کرد. در این جا باید از توزیع تجربی داده و اندازههای حاصل در آن توزیع و شکلگیری شاخص تأیید به دو دامنه استفاده کرد که میتواند یکی از شکلهای توزیع تجربی از قبیل بوتاستراپ یا جک نایف یا آرایش تصادفی باشد. نمونهای از تحلیلهای نادرست آماری استفاده از مجذور تاوکندال در پژوهش سجاد کریمی و همکاران (2014) است که باید از رگرسیون تعدیلی استفاده میشد.
9- همبستگیهای غیرعادی
ضرایب همبستگی غیرعادی، همواره از تعریف نادرست و یا ابزارسازی نادرست یا انتخاب نادرست ابزار ناشی نمیشود. گاهی هم به دلیل دادهسازی است. یکی از مثالهای بسیار واضح پژوهش حیدری ساربان و همکاران (93) است. در یافتههای آنان رابطه بین تعارضات و اختلافات با رضایت شغلی مثبت است و رابطه سرمایه اجتماعی و رضایت شغلی به سطح 977/ 0 میرسد. سرمایه اجتماعی در این مقاله همه واریانس تبیینکننده رضایت شغلی را در برگرفته است. بهتر شدن شرایط زندگی کاری، افزایش حقوق و ارتقاء به آن چیزی نمیافزایند.
یکی از همبستگیهای غیرعادی در پژوهش موقر و همکاران (2020) است. آنها در صفحه 190 نوشتهاند که هدف از انجام پژوهش مدلی با برازش مطلوب برای تبیین افسردگی بر اساس عوامل جمعیتشناختی و عوامل اجتماعی با نقش واسطهای عوامل شناختی است و مجدداً در صفحه 191 نوشتهاند تورش تجزیهوتحلیل اطلاعات از نوع مدلیابی ساختاری بود که به منظور برازش اولیه مدل از طریق معادلات ساختاری با نرمافزار AMOS و در سطح 05/ 0 آزمون شدند (ص 191 و 192) کاری که آنها هرگز انجام ندادند. آنها از رگرسیون چندگانه استفاده کردهاند و بهغلط آن را رگرسیون خطی نام نهادهاند. این سطح از خطاها را من در هیچ پژوهشی درزمینه تحقیق رابطهای تابهحال ندیدهام.
ازجمله همبستگیهای غیرعادی در پژوهش موسوی و همکاران (2019) است. در این مقاله مدلی بسیار ساده بهصورت مدل پیشانیدها (سن، جنسیت، درآمد، تحصیلات، نحوه تصرف مسکن، ...) و پسایندها (امکانات ساختمان، امکانات محلی، خدمات در دسترس، روابط با همسایگان، مشارکت اجتماعی، مشکلات اجتماعی) ترسیم شده است. این مدل بهوضوح نادرست است. چگونه رضایت از سکونت ممکن است بر ویژگیهای کالبدی آنطور که در شکل (1) صفحه 51 آمده است تأثیر گذارد؟ چون بهصورت طبیعی ویژگی کالبدی است که بر رضایت از سکونت اثر دارد. از طرف دیگر در این مقاله فقط همبستگی خام گزارش شده است (جدول 3، صفحه 57) درحالیکه ویژگیهای کالبدی مسکن و ویژگیهای اجتماعی بهصورت دو عامل مجزا آمده اما هیچ تحلیل عاملی روی آنها انجام نشده است. در مورد متغیرهای مستقل (جدول 4، صفحه 58) نباید همبستگیهای خام گزارش شود. در اینجا چون هیچ فرضیهای وجود ندارد باید از رگرسیونهای چندگانه (در اینجا گامبهگام یا پسرو ) استفاده شود. چون در این مقاله معمولاً رگرسیونهای تأییدی توصیه شده است و رگرسیون چندگانه نقد شده است. اینجا اتفاقاً باید از رگرسیون چندگانه استفاده شود.
البته باید توجه داشت که اگر متغیرهای بعدی افزوده شوند، ممکن است هم خطی ایجاد شود؛ به این معنی که روابط با همسایگان متغیر X1 با خشنودی شغلی y یک رابطه ساده دارد. افزودن مشارکت اجتماعی X2 ممکن است با خشنودی شغلی رابطه داشته باشد اما افزودن X2 علاوه بر آن ممکن است به دلیل رابطه با X1 و نیز رابطه با باقیماندههای مدلی که y را از x پیشبینی میکند بر نتایج تأثیر گذارد. اگر افزودن X2 پیشبینی را بهبود نداد اما همبستگی با X1 و y وجود داشت، در آن صورت اثر برآورده شده X1 کاهش یافته و حتی ممکن است معنیداری خود را از دست بدهد. دلیل آن این است که X1 و X2 همپوشی قابلملاحظهای دارند (X1 بهصورت منحصر بفرد y را پیشبینی نمیکند). بنابراین به دلیل افزایش متغیرهای پیشبین توان آماری کاهش مییابد (درجه آزادی خطا کم میشود). این متغیرها هرچند با یکدیگر میتوانند متغیر ملاک را پیشبینی کنند اما چون توان کاهش یافته، نمیتوانند فرضیه آن را تأیید کنند. این مسئله را همخطی متغیرهای پیشبین مینامند.
از موارد دیگر مقاله زارعی و همکاران (2019) است. در این مقاله ضرایب همبستگی ساده نخست محاسبه شدهاند. در صفحه 153 مدلی ترسیم شده است و ادعا شده که نمودار مسیر است. به جای ضرایب مسیر (ضرایب بتا) همان ضرایب همبستگی بر روی نمودار منتقل شدهاند. در اینجا همین همبستگیها برای نویسنده کافی بوده است (اما نه برای ما). مدل ترسیم شده نه مبتنی بر پیشینه پژوهش و نه دادههای تجربی است و معلوم نیست برچه مبنایی رسم شده است. بعداً جدولی از اثرات مستقیم و غیرمستقیم و اثر کل رسم شده است. در مرتبه سوم این بار اثر مستقیم همان ضرایب همبستگی ساده گزارش شده است و گاهی یک اثر غیرمستقیم هم گزارش شده است که آزمودن معنیداری اثرهای غیرمستقیم هم گزارش نشده است.
10- پیشفرض کاربرد الگوهای رگرسیون خطی برای دادههای رابطهای
در پژوهشهای رابطهای شناخت الگو مشخص کردن تابع انتظار و مشخصههای خطا امری مهم است. برای تابع انتظار ملاحظات عقلی یا نظری مدنظر قرار میگیرد که از طریق آن الگوی مکانیکی تابع انتظار شکل میگیرد که در سادهترین شکل، الگو و برآورد پارامتر با آن تعریف میشود.
این الگو باید برازش کافی با دادهها داشته باشد. معمولاً آن ملاحظات عقلی یا نظری که تابع انتظار را میسازد نادیده گرفته شده و بنابراین یک پیشفرض وجود دارد که الگوهای رگرسیون خطی تابع روابط خطی است. امری که لاجرم بدون دلیل توجیهی بر رگرسیون خطی است. در بسیاری موارد رگرسیون غیرخطی بین دادهها باید در نظر گرفته شود یا اگر دادهها بهصورت دادههای دورافتاده باشند در آن صورت رگرسیون چند کی (بامنی مقدم، خوشگویان فرد، 2004) بیشتر قابل توجیه است.
پیشفرض الگوی رگرسیون خطی که همواره بین متغیرها بدون توجیه عقلانی و منطقی وجود دارد منجر به حجم زیادی از دادههای تولیدشده توسط این الگوهاست، بنابراین کاربرد الگوهای رگرسیون خطی برای همه دادههای رابطهای نادرست است و در بسیاری از موارد ممکن است این روابط غیرخطی باشند.
در پژوهش خداداد کاشی و جاویدی (2012) این سؤال مطرح شده است که آیا آموزش بر فقر خانوادههای ایرانی اثر معنیدار دارد و آیا آموزش میتواند سبب کاهش فقر درآمدی و فقر مسکن و فقر بهداشت شود. روش تجزیهوتحلیل دادهها و تخمین مدل (ص 95) رگرسیون لاجیت و پروبیت است که نادرست است و باید از رگرسیون چندکی استفاده شود. این امر نیاز به بحث بسیار مفصلی دارد که در یکی از شمارههای آتی مجله به آن خواهم پرداخت.
11- تحلیلهای رگرسیون تأییدی و مدل معادلات ساختاری نادرست
تحلیل رگرسیون تأییدی را میتوان به سه دسته کلی تقسیم کرد که به ترتیب رگرسیون تعدیلی، رگرسیون فرونشان و رگرسیون میانجی است هر سه این نوع پژوهشها را میتوان با مدل معادلات ساختاری نیز انجام داد. در ایران تابهحال تحلیل فرونشان در هیچ پژوهشی گزارش نشده است تحلیل تعدیلی در مقالههای رفاه اجتماعی وجود ندارد اما تحلیل میانجی هم در کل پژوهشهای علوم انسانی و هم در پژوهشهای رفاه اجتماعی به کار رفته است. در تحلیل تعدیلی میتوان از رگرسیون سلسله مراتبی استفاده کرد. در ابتدا متغیر اصلی اول و پس از آن متغیر اصلی دوم را وارد معادله رگرسیون کرد و در نهایت حاصلضرب آن دو متغیر را که تعدیل یا تعامل متغیرها را نشان میدهد در معادله رگرسیون وارد کرد. تفاوت این نوع رگرسیون با رگرسیون گامبهگام (یا رگرسیونهای پیشرو و پسرو) در آن است که معادله آن این جمله ضربی را داراست که در تحلیل واریانس معادل تحلیل واریانس چندراهه است.
مدل معادلات ساختاری که تابهحال سه نسل را در طول یک قرن اخیر گذارنیده است اینک به ابزاری ساده در دست پژوهشگرانی تبدیل شده است که زیربناهای آن را بهدرستی نمیشناسند. به دلیل همین ناآشنایی انبوه مقالات زیادی تولید شده است که هیچ مفهوم روشنی ندارد که با کمک گرفتن از عنوان نمایشنامه شکسپیر میتوان آن را هیاهوی بر سر هیچ نامید.
نسل اول تحلیل معادلات ساختاری را گالتون (1888) برای تحلیل عاملی تأییدی پدید آورد که بعداً پیرسون و لی آن را به شکلی استادانه تدوین کردند. نسل دوم را که گام مهمی در مدل معادلات ساختاری است، رایت (1918) پدید آورد که تحلیل مسیر نامیده میشود. این مدل از ترکیب آن دو مدل معادلات ساختاری در نسل سوم پدید آمده است. این مدل، معادلات نسل اول و دوم را تحت عناوین مدلهای اندازهگیری و ساختاری ترکیب کرد که امروزه مبنای پژوهشهای زیادی است که در علوم انسانی به آن ارجاع میشود.
نمونهای از استفاده از معادلات ساختاری به جای رگرسیون در تحلیل تعدیلی را میتوان در پژوهش زمانی و عریضی (202) دید که شاید تنها پژوهشی باشد که از این شیوه به جای رگرسیون تعدیلی در تحلیل دادهها استفاده کرده است. ازآنجاکه معرفی آن در اینجا میتواند به کاربرد بیشتر این شیوه و استفاده از توانمندیهای آن منجر شود معادلات ساختاری مربوط به آن را در این بخش میآوریم.
نمودار (7): اثر تعدیلی در مدل مکنون مربوط به پژوهش زمانی و عریضی (202)
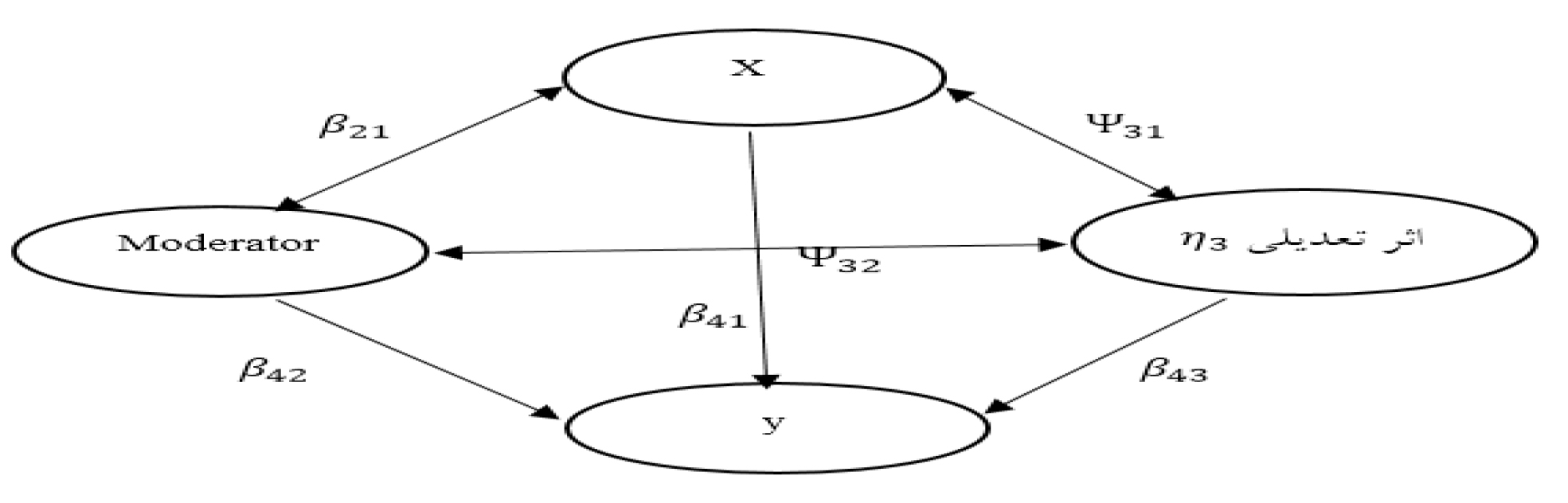
یکی از انتقادها به رگرسیون تعدیلی خطای اندازهگیری است که برآورد ضرایب رگرسیون را سوگیرانه میکند. درواقع این برآوردهای سوگیرانه سبب افت مقدار واقعی آن شده و کاربرد آن برای پیشبینی را محدود میکند. ازآنجاکه اثر تعامل از مرتبه دوم است و مقدار آن کوچک است، ممکن است به دلیل افت کلاً معناداری خود را از دست داده و پیگیری آن ناممکن باشد (درواقع این موضوع سبب کاهش توان آماری یا افزایش خطای نوع دوم میشود). از طرف دیگر در رگرسیون تعدیلی، برآورد ضرایب خطای رگرسیون همسوگیرانه بوده و بنابراین دو دلیل 1-تورش ضرایب رگرسیون و 2-تورش خطای معیار ضرایب رگرسیون دلایل کافی برای انجام مدل معادلات ساختاری به جای رگرسیون تعدیلی فراهم میکند.متغیر با رابطهη3=〖η 1 η〗 2 تعریف میشود و نقش متغیر تعدیلی را نشان میدهد. واریانس بین این متغیرها η KK و کواریانس آنها Ψ KL خواهد بود. در آن صورت بنا بر جروسکوگ و یانگ (1996) معادلات ساختاری برای اثر اصلی و اثر تعاملی شامل چهار معادله است.
برای اثرهای اصلی دو معادله شماره (2)y 1= t 1+λ 1 η 1+ε 1 و شماره (3) y 2= t 2 λ 2 η 2+ε 2 و برای متغیر تعدیلی میتوان معادله شماره (3) y 3= t 3+λ 3 η 3+ε 3 را نوشت. برای اثر تعاملی جروسکوگ و یانگ (1996) معادله زیر را مینویسند که جمله برجستهشده مربوطه به اثر تعاملی است که η 3=〖η 1 η〗 است. اگر متغیر ملاک برنامهریزی برای ورود به دانشگاه y 4 را بر اساس η 1 ، η 2 و η 3 بنوسم، داریم
معادله (4)y 4=t 4+λ 41 η 1+λ 42 η 2+λ 43 η 3+ε 4
و مقدارy 3 برابر (t 2+λ 2 η 2+ε 2 ) (t +λ 1 η 1+ε 1 )است. بنابراین T 3=T 1 T 2 و λ 1=T 2و λ 2=T 1 خاهد بود.
این مدل به لحاظ اصول راهنما شامل تشخیص مدل و در گام دوم گردآوری دادهها و در گام سوم روشهای برآورد و در گام نهایی ارزشیابی و بهبود است. متأسفانه در هیچ یک از مقالهها این اصول راهنما رعایت نمیشود که پرداختن به آنها مستلزم مقاله مستقلی است؛ اما در مورد مرحله اول که رابطه بین متغیرها در یک نمودار تجلی مییابد معمولاً مبتنی بر جهتهای علی در پژوهشهای مبتنی بر طرحهای علیتی از قبیل طرحهای طولی و آزمایشی نیست.
واژه علی که در مدل معادلات ساختاری به کار میرود با جهت نمودارها متفاوت است و علاوه بر آن نموداری که ترسیم میشود مدلهای همارز را نیز شامل میشود و معمولاً پژوهشها از آن ناآگاهند و شگفتزده میشوند که چرا قبل از آنها کسی این مدلها را بررسی نکرده است. غافل از آنکه در مجلههای معتبر بینالمللی داوران قوی حضور دارند که به این مطالب آگاهی دارند. بهعنوانمثال در پژوهش قاسمی و همکاران (1392) که مدل میانجی است، به تبیین رفاه اجتماعی و تأثیر آن بر احساس امنیت در شهر اصفهان پرداخته شده است. مدل میانجی بهصورت زیر است.
نمودار (8): مدل میانجی در پژوهش قاسمی و همکاران
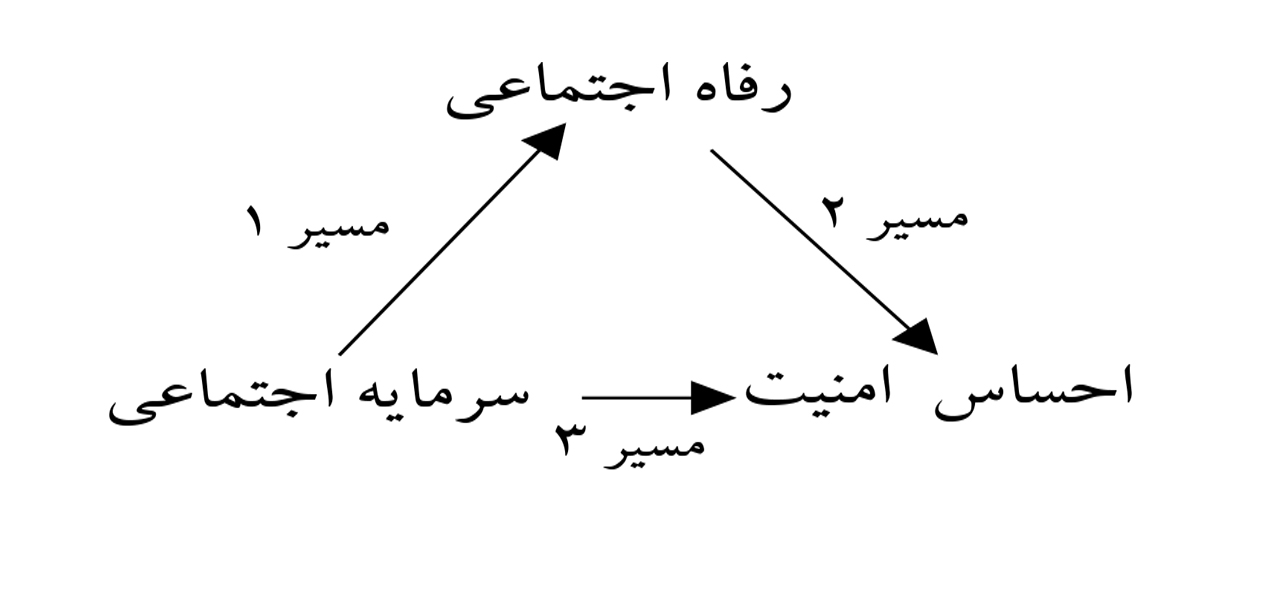
مدل فوق یک مدل میانجی است. در مورد مسیر یک که تأثیر سرمایه اجتماعی بر رفاه اجتماعی را نشان میدهد مؤلفین جملاتی از قبیل زیر را نوشتهاند(ص 26) به نقل از زاهدی و دیگران، 2009):
یافتههای تجربی متعدد، اهمیت سرمایه اجتماعی را رد ارتقای سطح توسعه اقتصادی جوامع نشان میدهد و ازآنجاکه سطح توسعهیافتگی بهطور بیواسطه معرف سطح نهاده اجتماعی است ارتباط میان سرمایه اجتماعی و توسعه را میتوان به ارتباط میان سرمایه اجتماعی و رفاه اجتماعی تأویل کرد و نتیجه گرفت که وجود سرمایه اجتماعی بالا میتواند سطح بالاتری از رفاه اجتماعی را تأمین کند.
آیا نمیتوان جمله آخر را به این صورت نوشت که رفاه اجتماعی بالاتر میتواند سرمایه اجتماعی بیشتری را تأمین کند و ازآنجا مسیر یک را کاملاً در جهت برعکس نوشت. در این صورت هم رفاه بر سرمایه اجتماعی و هم بر احساس امنیت تأثیر میگذارد و نمیتوان آن را مدل میانجی نامید. این یک مدل همارز است که مدل مخدوشکننده نام دارد. بهاینترتیب میتوان دید که با تغییر در کاربرد زبان میتوان بهسادگی مدل را تغییر داد و یک مدل همارز از آن را ساخت. جهتهای مورداشاره کاملاً ساخته زبان خصوصی است و یکبار دیگر گفتگوی هامپتی دامپتی را به یاد میآورد. تنها هنگامی میتوان این جهات را ترسیم کرد که مبتنی بر پیشینه پژوهشهایی باشد که در آن طرحهای پژوهشی بهصورت مطالعات طولی یا آزمایشی ارائه شده باشد. حال جمله زیر از فیتنر پاتریک، 1381) را مدنظر قرار دهید:
در رویکردهای نوین رفاه بر مسئولیت جامعه در قبال آحاد مردم تأکید شود که شامل شادکامی، تأمین امنیت و ترجیحات و نیازها و رهایی و مقایسه نسبی است.
مجدداً این جمله در جهت مسیر دو در مقاله مورد استناد قرار گرفته است. درحالیکه این جمله در مورد تأثیر رفاه بر احساس امنیت به ما چیزی نمیگوید. تنها میگوید که رفاه اجتماعی ازجمله شامل احساس امنیت است. بهاینترتیب جملاتی که در پیشینه نقل میشود نمیتواند این مدل را توجیه کند. همچنین در صفحه 4 آنها نظر شخصی خود را با این جمله بیان کردهاند که کارآمدی سیاستهای رفاهی به مقدار سرمایه اجتماعی در جامعه مربوط است. ازآنجاکه این جمله دیدگاه آنان است من میتوانم جملهای در جهت برعکس مسیر یک بنویسم که سرمایه اجتماعی به مقدار زیادی تابع رفاه اجتماعی در جامعه است. جملهای که نادرست به نظر نمیرسد. از طرف دیگر رابطه رفاه اجتماعی و امنیت یعنی مسیر دو را با این جمله مورد استناد قرار دادهاند.
به نقل از یزدانی، 1382:
یکی از پیامدهای اندیشهای درزمینه رفاه اجتماعی به نظریه اخلاقی دولت هگل بازمیشود. بر مبنای این نظریه، وظیفه اخلاقی دولت، حفظ امنیت و ایجاد اعتماد عمومی به کارکردهای جامعه در جهت حفظ منابع یکایک افراد جامعه است و عدالت نیز در این زمینه نقش به سزایی بر عهده دارد.
این جملات که در صفحه 7 مقاله آنها آمده برای توجیه مسیر دو در نمودار میانجی آنان است؛ اما میتوان از این جمله برداشت کرد که امنیت بر رفاه اجتماعی تأثیر میگذارد. امری که مدل میانجی را به یک مدل همرس تبدیل میکند. این مدل همارز با مدل میانجی است بنابراین مدل آنان را توجیه نمیکند. همچنین جملهای که در صفحه 4 نوشتهاند نیز به دلیل توجیه مدل میانجی غیر از یک زبان خصوصی نیست.
رفاه اجتماعی را نمیتوان صرفاً توسط مؤلفههای اقتصادی و مادی تضمین کرد و علاوه بر آن باید منابع جامعه مدنی ازجمله سرمایههای اجتماعی و گروههای گوناگون مردم را فعال و بسیج کرد.
چنانکه دیده میشود نمیتوان مدل میانجی را توجیه کرد و تعجبی ندارد که در این زمینه در سطح بینالمللی مقالهای ارائه نشده است؛ زیرا آنان زیربناهای توجیه چنین معادلاتی را نه زبان خصوصی که زبان علمی میدانند که در مجلات علمی با داوریهای دقیق بررسی میشود.
بهکرات مؤلف مقاله حاضر دیده است که پژوهشگران تعجب میکنند که چرا قبل از آنان کسی به فکر این رابطهها نیفتاده است. هنگامیکه به دنبال رابطههای میانجی میگردیم اکثر این مقالهها را ایرانیان نوشتهاند. حال به دلیل روانشناختی این مقالهها بازمیگردیم. پس از ورود دادهها به نرمافزارهای تحلیل مدل معادلات ساختاری پژوهشگران با دادههای برازش به سهولت آن را تأیید میکنند. بهاینترتیب این مقالهها از سه فرایند جملهپردازی در قالب زبان خصوصی، ورود دادهها و برازش به مرحله تأیید داده میرسد؛ درحالیکه شاخصهای برازش فقط پس از توجیه مدل پیشنهادی بر مبنای دقیق و استوار یعنی نظریههای شناخته شده یا طرحهای پژوهشی از قبیل طولی و آزمایشی امکانپذیر است.
در تفسیر دادهها نیز پژوهشگران دارای مشکلات جدی هستند. به این معنی که تصور میکنند توانستهاند مدل برساخته از زبان خصوصی را تأیید کنند و حالآنکه مدلهای همارز دیگری وجود دارد که با این شاخصها عیناً تأیید میشوند. اگر پژوهشگر بخواهد مدلهای همارز را رد کند از قبل باید توجیه نظری دقیقی برای مدل موردنظر ارائه داده باشد وگرنه امکان رد آن در مرحله پسین وجود ندارد.
در پژوهش قاسمی و همکاران متأسفانه تحلیل آماری نیز کاملاً غلط است. آنها ابتدا سه ضریب همبستگی ساده در مسیر یک و دو و سه را بررسی کردند که هر سه معنیدار بوده است. میدانیم که این سه فرضیه در مدل بارون و کنی (1986) فقط سه فرض اولیه هستند و فرض چهارم بسیار مهمتر است. با کنترل متغیر میانجی رابطه بین متغیر پیشبین و ملاک ناپدید میشود. آنها این فرضیه را بررسی نکردهاند و با نیمهکاره رها کردن تحلیل رگرسیون ناگهان از مدل معادلات ساختاری سعی کردند تحلیل میانجی را که نتوانستهاند در تأیید آن موفق باشند فقط بهصرف شاخصهای برازش تأیید کنند. یعنی تحلیل تأییدی در حالتی که مدل اصلی توجیه نشده است که کار کاملاً غلطی است. اثر غیرمستقیم یا میانجی که باید بر مبنای توزیع تجربی بوتاستراپ یا جک نایف انجام گیرد نیز گزارش نشده و بنابراین اصولاً مشخص نیست که اثر غیرمستقیم معنیدار است یا خیر. بهترین طرحهای تحلیل میانجی عبارت است از کاربرد میانجی در پژوهشهای آزمایشی است (کلاهدوزان، 2020).
12- ناهمخوانی معادله ریاضی زیربنایی با تحلیل آماری
معادله ریاضی باید هماهنگ با دادهها و طرح پژوهشی باشد که در تحقیق ارائه شده است. مثال عالی از این معادلات را میتوان در آمیگو و همکاران (2008) یافت که مجموعهای از معادلات برای صرف دارو در مغز در تصویرنگاری مغناطیسی از آن نوشتهاند. معلوم است که برای آنکه مشخص شود این معادلات با واقعیت انطباق دارند در مرحله بعدی باید دادههای شبیهسازی شده از انسان تطبیق داده شود.
کیوانآرا همکاران(2016) نیز معادلهای برای هوش مصنوعی نوشتهاند و آن را با ویژگی شخصیتی برونگرا هماهنگ کردهاند. سپس دادههای شبیهسازی شده را با آن منطبق ساختهاند که مغز افراد برونگرا این دادهها را مصرف میکنند. آنها این پژوهش خود را برای آزمون نظریه آیزنک مورداستفاده قرار دادهاند که طبق آن نحوه تأثیر داروها در مغز افراد برونگرا به شکل خاصی است. سپس دادههای مربوط به افراد معتادی که شخصیت برونگرا داشتهاند را با این مدل انطباق دادهاند. این دو شاهد از استفاده موفق از معادلات ریاضی است و در غیر این حالات استفاده از آن قابل توجیه نیست.
گاهی معادله ریاضی زیربنایی با تحلیل آماری ناهماهنگ است. مثلاً معادله زیربنایی تحلیل رگرسیون تعدیلی را پیشنهاد میکند اما پژوهشگر از تحلیل رگرسیون چندگانه استفاده کرده است. نمونه آن مقاله رنانی و مؤیدفر (1999) است که آن را در سطح پایینی در مقالات سرمایه اجتماعی قرار میدهد. بااینحال به دلیل محدودیت فضا فقط به بعضی از این خطاها در این مقاله اشاره میکنم. نخست به خطاهای تحلیل دادههای آن پرداخته و سپس فضای مفهومی آن را موردنقد قرار میدهم.
از نظر روانسنجی اگر ابزارها دارای پایایی و اعتبار نباشند، نباید به دادههای آن اعتماد کرد. در پژوهش آنان روی هم 35 سؤال مربوط به سه مقیاس است. درحالیکه فقط یک ضریب پایایی برای مجموع سه مقیاس گذاشته شده است. گیفورد در کتاب معروف روانسنجی خود تعداد 35 سؤال کاملاً نامربوط به هم را انتخاب کرده و روی یک نمونه آنها را اجرا میکند. او ضریب پایایی 75/ 0 را به دست میآورد که کاملاً بیمعنی است. دلیل آن این است که طبق یک قضیه معروف در روانسنجی با افزایش تعداد سؤالات ضریب پایایی افزایش مییابد. از طرف دیگر آنها به یک مدلسازی ریاضی میپردازند که در تحلیل دادههای آنها حضور ندارد و کاملاً نامربوط با شیوه تحلیل دادههای آنها است.
آنها نوشتهاند که افراد علاوه بر آن که از ویژگیهای هویتی و معرفتی فرد بهصورت مستقل تأثیر میپذیرد، تحتتأثیر اثرات متقابل این ویژگیها بر یکدیگر نیز قرار میگیـرند. بیان ریاضی این تفسیر میتواند بهصورت رابطه زیر مدلسازی شود:
معادله (5)
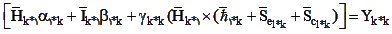
معادله (6)
.jpg)
معادله (7)
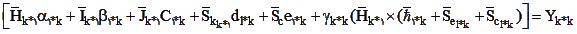
H: ماتریس ویژگیهای معرفت است که به تعداد افـراد جامعـه دارای مقـادیر متفـاوتی است. در اینجا تعداد افراد جامعه k و تعداد ویژگیهای معرفتی z است. [ ] (1) kz k *z H = h I ماتریس ویژگیهای هویت است که به تعـداد افـراد جامعـه دارای مقـادیر متفـاوتی است.معادله (6)
معادله (7)
در این جا یک رابطه ضربی تعریف شده است که مستلزم تحلیل تعدیلی است. در متن مقاله آنها این رابطه ضربی که بسیار مهم هم هست ناپدید شده است. درواقع نتایج آنها به کمک تحلیل حداقل مجذورات (OLS) و رگرسیون معمولی بوده است. درحالیکه نیاز به رگرسیون تعدیلی داشته است. معلوم نیست چرا آنها چنین فرمولی را که مربوط به متن دیگر است در اینجا قرار دادهاند.
مؤلفههای سرمایه اجتماعی بهصورت پایبندی به هنجارها، قابلاعتماد بودن و حـضور فعـال در شبکههای اجتماعی بوده است. بنابراین ویژگیهای افراد جامعه در ارتباط با سه مؤلفه فـوق، در ماتریس دیگر قابل جمعآوری است که در آن تعداد سطرها به تعـداد سـه مؤلفه سرمایه اجتماعی ـ پایبندی به هنجارها، قابلاعتماد بودن و حضور فعال در شبکههای اجتمـاعی و تعداد ستونها به تعداد افراد جامعه خواهد بود. در ماتریس D ویژگیهای افراد در ارتباط با مؤلفههای سرمایه اجتمـاعی را بـه ایـن مفهوم که هر فرد چه اندازه به هنجارها پایبند است؛ چه قدر قابلاعتماد است و تا چه حد در شبکههای اجتماعی مشارکت میکند نشان میدهد.
حاصلضرب ایـن مـاتریس در ماتریس «تعامل ارزشهای درونی افراد جامعه» بهصورت: (6) D*Y=G ماتریس درجه برخورداری افراد جامعه از مؤلفههای سرمایه اجتمـاعی اسـت کـه در تعاملات و مبادلات اجتماعی قابلیت انباشته شدن و تبدیل به سرمایه اجتماعی است، یعنی ماتریس G را نشان میدهد.
در مقاله مویدفر و همکاران () هویت دینی مطرح شده است که آن هم جنبه کاملاً انفعالی و برونزاد دارد. هویت ابعاد بسیار مهم و زیربنایی دیگری دارد که عبارت از طبقه اجتماعی، جنسیت و قومیت علاوه بر هویت دینی است. این هویتها هم با یکدیگر اثر تعاملی دارند که در پژوهشهای اجتماعی بهعنوان مدلسازی تعامل متقاطع شهرت یافته است (مثلاً نگاه کنید به سنگ و همکاران، 2015). درواقع هویت اجتماعی از تعامل این متغیرها شکل میگیرد. روشهای تعامل متقاطع درواقع باید کاملتر نوشته شود. درواقع معادله (1) را به شکل کاملتر میتوان بهصورت زیر درآورد:
معادله (8)
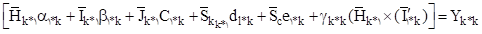
همانطور که گفته شد معادلهای که مویدفر و همکاران () نوشتهاند ربطی به تحلیل دادههای آنها ندارد؛ چون اصولاً رگرسیون تعدیلی انجام ندادهاند. هر رابطه ضربی از نوعی که آنها نوشتهاند یک رابطه تعاملی است اما من پیشنهاد میکنم که یک رگرسیون سلسله مراتبی از نوع تعدیلی انجام شود تا مشخص شود آیا ماتریس حاصل بیشتر تحت تأثیر (الگوی مارکسی)، (الگویهانتیگتونی، مویدفر) یا است. روشهای تحلیل ازایندست بسیار دشوارتر از معادله (2) بوده و درزمینههای متفاوت در وارنر و براون ، 2011 شرح داده شدهاند.
13- تغییر ارجاع به پیشینهساختگی و مطالعه ناکافی پیشینه
در بسیاری از پژوهشهای مربوط به متغیر سوم ایجاد ارتباط بین متغیرها فقط از طریق رابطهای است که در ذهن پژوهشگر تصور میشود و کاملاً برساخته اوست و با واقعیت آن رابطه منطبق نیست. بهعنوان نمونه به پژوهش اصغری و همکاران (2021) که در بخش پنج به آن پرداختهایم بازمیگردیم. در این تحقیق سعی میشود رابطه بین سه متغیر خودمهارگری و شفقت به خود و فداکاری همسر بهصورت یک رابطه میانجی توجیه شود. طبق این نوع پژوهشها نخست سه متغیر بیان شده و تعاریف آن ارائه میشود و سپس رابطه بین دوبهدوی متغیرها باید با پژوهشهای پیشین توجیه شود. پژوهشگر بدون آنکه بداند که معنی اینکه متغیری عامل تأثیرگذار حفاظتی دارد به معنی آن است که آن متغیر تعدیلی است، بیان میکند که خودشفقت بین دو متغیر دیگر نقش میانجی دارد و با اشاره به پژوهش ممتازی به نظریه سپر محافظتی استناد میکند.
همانطورکه قبلاً در همین مقاله بیان شد نظریههای سپر حمایتی همواره نقش تعدیلی و نه میانجی دارند. پژوهشگرانی که به تحلیل متغیر سوم میپردازند و نیز داوران آنها باید بتوانند بین عبارتهای زبانی و استفاده از تحلیلهای آماری تناظری برقرار کنند. پژوهشگر اما در همان صفحه به نقل از بکدان و همکاران (2016) مدلی را پیشنهاد میکنند که خودشفقتی (شفقت بر خود) بهصورت متغیر میانجی بین دلبستگی اضطرابی و قدردانی از بدن است.
اینکه خودشفقتی متغیر میانجی بین متغیرهای دیگری باشد توجیهکننده اینکه در یک تحلیل میانجی بهعنوان متغیر ملاک قرار گیرد نبوده و دو متغیر دیگر نیز هیچ ارتباطی به این پژوهش نداشته و بنابراین منابعی نیستند که توجیهکننده رابطه میانجی باشند. استفاده از پژوهشهای نامربوط در بسیاری موارد منجر به ساخت پژوهشهای با متغیر سوم (میانجی، فرونشان، مخدوشکننده و همرسان) بدون مفهوم و بیمعنی شده است. پژوهشی که حداقل بین دو متغیر در تحلیل میانجی در پژوهش آنان ارتباط ایجاد میکند پژوهش اوزیل و هفتز (2014) است. نویسندگان یک رابطه همبستگی ساده بین دو متغیر پژوهش خود را از آن نقل میکنند که خودمهارگری بالا منجر به خودشفقتی بیشتر میشود که درواقع متغیر ملاک و پیشبین پژوهش آنهاست.
متأسفانه این ارجاع غیرواقعی است و پژوهش اوزیل و هفتز (2014) یک پژوهش آزمایشی است که در آن متغیر شفقت به خود وجود ندارد. در پژوهش مذکور با دستکاری خودمهارگری سعی شده که رفتار عقلانی در تصمیمگیریهای اقتصادی بررسی شود و ارجاع به شفقت به خود کاملاً نادرست بوده و فقط برای توجیه میانجی استفاده شده است. این مسئلهای است که معمولاً در تحلیل میانجی دیده میشود. چون توجیه رابطه بین متغیرها مهمترین گام در این تحلیل است فقدان آن در بیشینه را، با ارجاع نادرست میتوان جبران کرد.
آنها با ارجاع به پژوهش سلطانزاده (2012) رابطه ساده بین شفقت به خود و رفتارهای فداکارانه را متذکر شدهاند و به نقل از استفنسون (2014) بیان کردهاند که پاسخ همدلانه از سوی همسر بهمثابه یک ضربهگیر در برابر اثرات منفی عمل میکند که مجدداً تحلیل آماری این فرضیه اثر تعدیلی و نه اثر میانجی است. بنابراین در پیشینه هیچ دلیل موجهی برای رابطه میانجی وجود ندارد و نمیتوان این مدل را حتی بر پایه پیشینهها تجربی توجیه شده دانست.
متأسفانه مقالات متعددی در ایران وجود دارد که با چنین توجیهات نادرستی سعی میکنند رابطه با متغیر سوم را بهگونهای توجیه کنند و بسته به اراده پژوهشگر ممکن است بهصورت متغیر میانجی یا تعدیلی و یا فرونشان درآیند. شفقت به خود شامل شش زیر مقیاس است که مهربانی به خود، قضاوت خود، ذهنآگاهی، همانندسازی، اشتراکات انسانی و انزوا این زیرمقیاسها را شکل میدهند. پژوهشگران آن را به یک متغیر تقلیل دادهاند تا از پیچیدگی آماری آن بکاهند اما ناخواسته دچار خطای دیگری شدهاند؛ اینکه زیرمقیاسها جمعپذیر نیستند و بنابراین نمیتوان آن را بهصورت یک متغیر یکپارچه درآورد و در بحث و نتیجهگیری از آن دچار خطایی میشوند که توجیهپذیر نیست. پژوهشگران در صفحه 136 مینویسند که جنبههای مثبت شفقت به خود چون مهربانی به خود، حس انسانیت مشترک، ذهنآگاهی بهصورت مثبت و سختگیری و انتقاد از خود میتواند دارای جنبه منفی بوده و احساس دوگانه را در فرد تقویت کند. مثلاً پژوهشگران در توجیه رابطه میانجی نوشتهاند:
از طریق مهربانی به خود میتواند تصویری مثبت ایجاد کند و این تصویر مثبت از خود مطابق با این مفهوم که فردی است نگران همسر ... ممکن است فعالیتها و اموری را انجام دهد که تمایل و رغبتی به آنها ندارد؛ اما چون با همسرش احساس خوبی خواهند داشت، فرد از طریق آگاه بودن از تجربیات در زمان حال حاضر به اهداف طولانیمدت دست خواهد یافت.
در اینجا دو متغیر شفقت به خود و فداکاری ادراکشده همسر به ترتیب دارای شش و دو زیر مقیاس است و چون در این پژوهش این زیرمقیاسها در تحلیل میانجی وارد نشدهاند پژوهشگر ناگزیر به جای آنکه بر مبنای دادهها سخن گوید تصورات خود را شرح میدهد بدون آنکه پشتوانه پژوهش از دادههای خود را داشته باشد؛ مثلاً خودشفقتی فقط به مهربانی تقلیل مییابد که یکی از زیرمقیاسهاست و نمیدانیم که رابطه این زیرمقیاس با متغیرهای دیگر چگونه است.
درعینحال چون فداکاری ادراکشده از همسر و فداکاری خود فرد که دو زیرمقیاس هستند با یکدیگر ترکیبشده معلوم نیست که در هر مورد چه تأثیری بر خودمهارگری داشته است. مضاف به اینکه به نظر میرسد خودمهارگری بر رفتار فداکارانه فرد اثر دارد و نه برعکس. زیرا فرد باید از لذتهای خود به نفع همسر چشم پوشد که نیاز به خودمهارگری بالایی دارد. درواقع این رابطه در تحلیل متغیرهای سوم نه تحلیل میانجی بلکه تحلیل همرس است و بنابراین همه این گفتگو که مربوط به تحلیل میانجی است بیاعتبار میشود.
هیچ مزیتی بر میانجی گرفتن رابطه بین متغیرها وجود ندارد و درک عقلایی بین آنها به تحلیل همرس که مدل همارز میانجی است نزدیکتر است. بهخصوص با توجه به آنکه مدل همارز تحلیل میانجی آنها حتی توسط پیشینههای تجربی نیز پشتوانهای ندارد و کاملاً همبستگی خیالی در ذهن پژوهشگر پدید آمده است که تابع زبان خصوصی است و آسیب در تحلیل متغیرهای سوم از همینجا ناشی میشود.
پژوهشگران فقط رابطه ساده بین متغیرها را گزارش کردهاند که به نظر در سطح بسیار بالایی است و تا حدی مشابه همبستگیهای غیرعادی است. خودمهارگری با مهربانی (53/ 0=r) با اشتراکات انسانی (48/ 0=r) ذهنآگاهی (53/ 0=r) شفقت به خود 31/ 0=r (ص 132/ جدول 2) بااینحال در مورد این همبستگیهای ساده بحثی نشده که چرا بعضی از آنها مثبت و بعضی منفی است و هنگامی که به سراغ متغیر سوم میروند با شاخص برازش رابطه میانجی را تأیید شده میبینند که به دلیل ناآگاهی آنان از مدلهای همارز است. در جدول 3 ادراک رفتارهای همسر و شفقت به خود با یک ضریب همبستگی ساده گزارش شده است. درصورتیکه اولی شامل دو زیرمقیاس و دومی شامل شش زیر مقیاس است و این همبستگی ساده در شناسایی رابطه بین متغیرها نمیتواند توجیهکننده باشد. بخصوص اینکه ادراک رفتارهای همسر یک متغیر در مورد خود فرد و همسر او است که رفتار دوتایی را گزارش میکند و بر هم نهی آنها کاملاً با فلسفه این متغیر مغایرت دارد چون یک نفر فداکاری میکند و دیگری که ابژه این فداکاری است نمیتواند همزمان فرد فداکار باشد. شفقت نیز دارای مقیاسهایی است که با یکدیگر در تضاد هستند و جنبههای مثبت و منفی شفقت را شرح میدهند. جمعپذیری آنها به لحاظ روانسنجی نادرست و امکان تحلیل از این متغیرها را از میان میبرد. در واقع آنچه به جای آن مینشیند نوعی زبان خصوصی بیحاصل است.
بعضی مواقع پژوهشگران برای توجیه متغیر سوم به پیشینهای متوسل میشوند که آن را بهدرستی مطالعه نمیکنند. قبلاً به پژوهش اوزیل و هفتسز (2014) اشاره کردیم که برای توجیه رابطه بین کنترل خود و شفقت خود مورد استناد آنها قرار گرفته بود؛ درحالیکه چنین رابطهای در آن پژوهش وجود ندارد و بحث دیگری در آن پژوهش مدنظر قرارگرفته که متغیر کنترل خود را به متغیر فداکاری همسر مرتبط میکند؛ اما کاملاً در جهت برعکس رابطهای که پژوهشگران در تحلیل میانجی خود گنجانیدهاند. متغیر کنترل خود موردعلاقه امانول کانت، فیلسوف بزرگ آلمانی، بود. او در کتاب «نقد عقل ناب» خود این دیدگاه را مطرح کرد که کنترل، خود منجر به فعالسازی عقل ناب میشود که منفعت شخصی را هدایت میکند. این رویکرد بهصورت غریزه خودخواهی پدیدار میشود که در متون اقتصادی محرک منفعت شخصی است؛ رویکردی که بعداً آین رایند (1963) آن را نگرهپردازی کرد که در نمودار زیر دیده میشود.
نمودار (9):

همانطور که دیده میشود برخلاف استدلالهای نویسندگان مقاله که بر هیچ نظریهای استوار نیست خودکنترلی نه با متغیر فداکاری همسر که ضد رفتار خودخواهانه است، بلکه با رفتار خودخواهانه مرتبط است.
ممکن است نویسندگان مقاله بتوانند با جملهپردازی برعکس آن را توجیه کنند. درواقع در مورد هر دو متغیری در عالم میتوان بهنوعی مطلب ارائه داد که آنها را در هر جهتی که میخواهیم به هم مربوط کنیم. اما اگر از نظریهها یا فرضیههای علمی استفاده کنیم ممکن است همه آنها نادرست باشند و این ازجمله آن موارد است.
پژوهشگران بین خودمهارگری و رفتار فداکارانه همسر ضریب همبستگی 53/ 0 را گزارش دادهاند درصورتیکه بر مبنای نظریه مقالهای که بهعنوان پیشینه آوردهاند این همبستگی قابل توجیه نیست. کاری که آنها میتوانستند انجام دهند عدم ارجاع به این مقاله بود که میتوان آن را سوگیری پیشینه مثبت (عریضی و فراهانی، 2008) دانست؛ اما آنها نوشتهاند که رفتارهای فداکارانه همسر میتواند نقش مؤثری در خودمهارگری افراد داشته باشد (ص 140). آنها باید با ارجاع به این نظریه توجیه میکردند که رابطه متغیرها در جهت برعکس است و نه آنچه آنها فرض کردند. ارجاع به پیشینه در پژوهش آنها در بقیه مواقع کاملاً به مدل آنها بیربط است. مثلاً چگونه پژوهش خستهمهر که فداکاری همسر را بهعنوان متغیر میانجی بین کیفیت زوجی و دلبستگی آورده میتواند مورداستفاده پژوهشگران قرار گیرد؟ آنها همچنین یافتههای خود را هماهنگ با تانجنی و همکاران (2004) و صالح حسینی (2015) آوردهاند که در هر مورد نمیتوان آن یافتهها را به این کار نسبت داد.
بحث
در پژوهش حاضر بهطورکلی دریافتهای نادرست از پژوهشهای رابطهای و ارائه آن در مجله رفاه اجتماعی مورد بررسی قرار گرفته است. پرواضح است که پذیرش یک مقاله در مجله پایان کار نیست و حتی بعد از چاپ مقالهها ممکن است ریتراکت شوند. نویسنده این مقاله، برخی از این مقالهها را سزاوار ریتراکت شدن میداند و در این جا به آنها اشاره میکند. در آخرین کتاب نگارش وی ، فصل مهمی به ریتراکت اختصاص یافته است. او این فصل را با معروفترین نویسندهای که هر دانشجوی روانشناسی وی را میشناسد یعنی هانس یورگن آیزنک آغاز کرده است. کسی که در یکی از کتابهای سهگانه معروفش یعنی واقعی واقعیت و خیال در روانشناسی (سومین کتاب) نوشته بود:
دو کتاب پیشین را اغلب «بحثِانگیز» به شمار آوردهاند. در وقع خود من به این لقب «بحثانگیز» چنان عادت کردهام که هر وقت رئیس یک جلسه هنگام معرفی من اشارهای به آن نمیکند نوعی احساس محرومیت به من دست میدهد.
اینک بیش از شصت مقاله او با واژه Retract که بر صفحات مقالهاش و با حروف درشت آمده رد شده است. کلمه Retracter فرانسوی است که در قرن چهارم به معنی بازگرداندن به عقب بوده است که در لاتین rectractus به همین معنی گرفته شده است. کلمه لاتینی retractionem هم به معنی تردید و هم به معنی لغو است. سنت آگوستین کتابی با عنوان Retractions (بازپسگیری) نوشته است که به معنی اصلاح نوشتههای قبلی اوست. کلمه ریتراکت درواقع از او گرفته شده است و اینک در متون روش تحقیق بهعنوان اصطلاحی فنی به کار میرود.
میدانیم که این جنبش جدید از ورزش و پسگیری مدالهای ورزشکاران متقلب آغاز شده است (بهطور مشخص بن جانسون، متولد 1961). عریضی (1401) هفت توصیه برای کاهش ریتراکت (صفحات 129 تا 132) آورده است. خطای آیزنک از جایی آشکار شد که آیزنک سعی کرد با دادههای ساختگی نشان دهد که یک میانجی که او آن را شخصیت مستعد سرطان نامیده بود سبب سیگارکشیدن میشود و خود سیگار تأثیری بر سرطان ندارد. درواقع برای ریتراکت شدن مقالههای او تلاش بسیاری انجام شد.
در زیر در ستون آخر به مقالههایی که شایسته ریتراکت شدن هستند هم اشاره شده است:
ردیف دریافت نادرست خطا دریافت بخش مربوط در مقاله نوع خطا آیا شایسته ریتراک هست؟
| ردیف | دریافت نادرست | خطا | دریافت | بخش مربوط در مقاله | نوع خطا | آیا شایسته ریتراک هست؟ |
| 1 | زراع و زراع (2015) | + | این دریافت غلط که multiple همان چندمتغیره است. درحالیکه آن را بهصورت رگرسیون یک متغیره استفاده میکند. | اول | به جای رگرسیون چند متغیره از رگرسیون چندگانه استفاده شده است. | خیر |
| 2 | غفاری و همکاران (2019) | + | عدم درک این نکته که اگر r12>0.7 باشد (در پژوهش آنان 97/0) حتی اگر ابزارهای متفاوتی برای سنجش آنها به کار رفته باشد دو متغیر یکی هستند. | اول | عدم توجه به اعتبار سازه سرمایه اجتماعی و نهادی | خیر |
| 3 | بیدل و همکاران (2015) روشنفکر و ذکایی (2006) | + | این دریافت غلط که اگر نامگذاری ناممکن بود پس تحلیل عاملی را میتوان بهصرف برخی از گویهها نجات داد | دوم | نامگذاری نادرست عامل در تحلیل عاملی | خیر |
| 4 | اصغریکما و همکاران (2021) | + | عدم درک «مدل علی» در مدل معادلات ساختاری (SEM) که فقط مدل تصوری پژوهشگر با شاخص تأیید نمیشود بلکه مدلهای دیگر هم تأیید میشود. | سوم | استفاده نادرست از شاخصهای برازش و عدم تمایز بین مدلهای همارز | به این دلیل پاسخ منفی است. ولی جای دیگر در مقاله به آن اشاره شده است. |
| 5 | نامنی و همکاران (2016)، نامنی و قربانی | + | این دریافت غلط همهجا گستر که ماشین (کامپیوتر و نرمافزار) میتواند فرضیهای را مستقل از تفکر و پژوهشگر شاخته یا تأیید کند. | چهارم | تصور اینکه کامپیوتر میتواند (یا برنامه کامپیوتر) فرضیهسازی کند. | خیر |
| 6 | اصغر کما و همکاران (2021) | + | این دریافت که برای میانجی بودن یک متغیر، میتوان مستقل از پژوهش پژوهشی را یافت که در آن متغیر موردنظر میانجی باشد. | پنجم | این تصور نادرست که یک متغیر در ذات خود میانجی است و ربطی به متغیرهای قبل و بعد ندارد. | به این دلیل پاسخ منفی است. ولی جای دیگر در مقاله به آن اشاره شده است. |
| 7 | ایرانی و همکاران (2018) و محمود علیلو و همکاران (2014) | + | این دریافت از ترجمه غلط یک مقاله خارجی که راهنمای پژوهشگران بوده است ناشی میشود. | پنجم | جابهجا گرفتن متغیر تعدیلی (moderator) و میانجی (mediator) | خیر |
| 8 | پاکنهاد و همکاران (2020) |
| این دریافت نادرست که دو آماره که توزیع نرمال دارند، حاصلضرب آنها هم توزیع نرمال دارد. | پنجم و هشتم و یازدهم | استفاده از آماره نادرست (سوبل) به جای توزیع تجربی بوت استراپ برای میانجی | خیر | |||
| 9 | گزی و محمدیآریا (2015)، نیکوگفتار (2014) | + | این دریافت غلط که میتوان با هر پیشینهای و بدون توجه به چهارچوب نظری حاکم بر تحقیق فرضیهسازی کرد. | پنجم و ششم | پیشینههای نامرتبط | خیر |
| 10 | حقیقتیان و جعفری | + | هفتم | محدودیت دامنه دادهها | آری، به دلیل آن که بخشی از دادهها ساختگی است. | |
| 11 | محمودعلیلو و همکاران (2014) | + | پنجم | عدم توجیه نقش میانجی و پیشینه نامناسب | خیر | |
| 12 | زارعی، میرزائی، مهاجری (2019) | + | این دریافت غلط که میتوان دادهها را با اصطلاحات آماری ولی بدون توجه به روابط دقیق ریاضی بین آنها نوشت. | نهم | دادهها بهوضوح ساختگی است، چند ضریب همبستگی درصدها، مجدد بهعنوان ضرایب میسر بکار رفته است. | آری، دادهها ساختگی است. |
| 13 | موقر و همکاران | + | دهم | گزارش همبستگی غیرعادی | آری، دادهها ساختگی است | |
| 14 | قاسمی و همکاران (2013) | + | این دریافت که شاخص برازش میتواند یک رابطه که نه منطبق با حدس علمی ونه منطبق با پیشینه پژوهش است تأیید کند. | دوازدهم | عدم توجیه یا پیشینه برای میانجی | خیر |
| 15 | رنانی و مویدفر (1999) | + | معادلات ریاضی و مدلسازی ریاضی با آمار بکار رفته هماهنگ نیست. | مورد دوازدهم، میتوانستیم تحت عنوان هفت هم آن راقرار دهیم، اما در این جا نویسنده به معادله ریاضی استناد کرده که شیوه تحلیل او را زیر سؤال میبرد. | معادله ریاضی نیازمند یک تحلیل تأییدی (از نوع تعدیلی است. نویسندگان بجای آن تحلیل از نوع اکتشافی (رگرسیون چندگانه) انجام دادهاند. | خیر |
همه پژوهشهای بررسی شده در این مقاله بهنوعی یا با درک نادرستی از تحلیل عاملی، تحلیل مسیر و تحلیل مدل معادلات ساختاری (SEM) و یا عدم تمایز بین تحلیلهای اکتشافی و تأییدی و یا با درک نادرست رگرسیون ازجمله تفاوت قائل نشدن بین رگرسیون چندگانه و رگرسیون چند متغیره روبرو بودند. به همین دلیل خطوط راهنما هم برای نویسندگان و هم برای داوران در زیر ترسیم شده است.
*خطوط راهنما برای تحلیل عاملی، تحلیل مسیر و تحلیل مدل معادلات ساختاری
1- تحلیل عاملی به دو دسته کلی تحلیل عاملی اکتشافی (EFA) و تحلیل عاملی تأییدی (CFA) دستهبندی میشود. در نوع اول فرضیهای وجود ندارد و تنها موقعی موفقیتآمیز است که گویههایی که در زیر یک عامل میآیند یک مفهوم (روح) مشترک داشته باشند و اگر چنین مفهوم مشترکی وجود نداشته باشد تحلیل عاملی اکتشافی نباید صورت گیرد.
2- تحلیل عاملی تأییدی که مبتنی بر فرضیه ساخته میشود همواره باید بعد از تحلیل عاملی اکتشافی صورت گیرد. این دو نوع تحلیل عاملی باید روی دو نمونه مجزا (و نه خطایی آشکار که در پژوهشهای ایران به فراوانی دیده میشود) نه روی یک نمونه انجام شود؛ چراکه مشخص است که روی همان دادهها، شاخصهای برازش مطلوب خواهند بود و نمیتوان فرضیه را تأیید کرد.
3- اگر فردی ابرازی را طراحی میکند حتماً باید روی آن تحلیل عاملی اکتشافی انجام دهد. اگر نتیجه موفقیتآمیز نبود تحلیل عاملی نباید گزارش شود؛ اما فرد میتواند با شیوههای معمول آماری فرضیههای خود را دنبال کند. بسیاری از سازهها، سالها در تحلیل عاملی موفق نبودهاند، این به معنای رد آن سازهها نیست. این نشاندهنده تفوق فلسفه علم کوه بر پوپر است.
4- اگر زیرسازهها با یکدیگر رابطه (بهصورت نظری) دارند باید از تحلیل مایل استفاده کنند؛ و گرنه (در صورت استقلال) باید از تحلیل متعامد استفاده شود.
5- هرگاه ابزاری از جامعه دیگر (مثلاً انگلیسی) ترجمه میشود باید تحلیل عامل تأییدی (CFA) با دادههای جامعه ایرانی انجام شود.
6- تحلیل مسیر که توسط سؤال رایت (در مطالعات ژنتیک) در دهه چهل قرن بیستم انجام شد در یک مدل یک طرفه (که لزوماً به معنی علیت فلسفی نیست) به محاسبه ضرایب مسیر بر مبنای ضریب همبستگی منجر میشود. هر چه متغیرها در تحلیل مسیر بیشتر و پیچیدهتر باشند این ضرایب مسیر از معادلات ریاضی پیچیدهتری به دست میآیند. یکی گرفتن ضریب همبستگی و ضریب مسیر یک تقلب آشکار است که داوران میتوانند بهسادگی آن را کشف کنند.
7- تحلیل عاملی که توسط اسپیرمن در آغاز قرن بیستم به وجود آمد در ترکیب با تحلیل مسیر در پایان قرن بیستم به مدل معادلات ساختاری (SEM) انجامید. در این مدل شاخصهای برازش به معنی تأیید فرضیههای محقق نیست. محقق باید از طرحهای پژوهشی قوی در کنار پیشینهای قوی برای ساخت فرضیهها استفاده کند و نداشتن این پیشینه یا طرح نباید منجر به تأیید فرضیه فقط به کمک شاخصهای برازش شود.
8- پژوهشگرانی که به مورد هفتم واقف نیستند بدون استفاده از طرحهای پژوهشی قوی یا پیشینه مناسب و فقط بهصرف شاخصهای برازش ممکن است فرضیهای را تأیید کنند. نویسنده این مقاله هیچ امکان دیگری را در پژوهشهای ایرانی نیافته است که بهاندازه این درک نادرست به مقالههای نادرست انجامیده باشد. این پژوهشگران تصور میکنند کافی است پیشینههایی برای متغیرهای تحلیل میانجی ذکر کنند و بقیه کارها را شاخصهای برازش انجام خواهد داد. همان ایده دوربین عکاسی کداک:
You press the bottom. We do the rest
9- پژوهشگرانی که به مورد هفتم واقف هستند ولی پیشینه مناسب را نمییابند، ممکن است به خلق این پیشینه بپردازند. این مقالهها حتماً باید ریتراکت شوند. بنابراین اگر داور به این پیشینه مشکوک شد باید آنها را شناسایی کند. این نوع پژوهشگران از شعار عبری استفاده میکنند که در اقتصاد مشهور شد.
Create out of Nothing
*** خطوط راهنما برای تحلیل عاملی اکتشافی و تأییدی
1- برخی از روشهای آماری (مثل تحلیل عاملی اکتشافی، رگرسیون چندگانه، تحلیل واریانس با آزمونهای تعقیبی پسینی) رویکردهای اکتشافی در آمار هستند. آنها فرضیه ندارند و نوشتن فرضیه برای آنها کاملاً ساختگی است.
2- برخی دیگر از روشهای آماری (مثل تحلیل عاملی تأییدی، رگرسیونهای سلسله مراتبی، تحلیل واریانس با آزمونهای تعقیبی پیشینی) رویکردهای تأییدی در آمار هستند. آنها برای تأیید فرضیه مورداستفاده قرار میگیرند.
3- مدل معادلات ساختاری یک رویکرد تأییدی است.
4- همه روشهای تأییدی یا باید دارای طرحهای قوی (مثل طرحهای طولی یا آزمایشی) باشند یا دارای پیشینه بسیار قوی باشند.
5- همه مدلهای ریاضی میتوانند (رویکرد اکتشافی) و یا (رویکرد تعدیلی، یکی از انواع رویکردهای تأییدی) باشند.
6- معروفترین رویکردهای تأییدی شامل رویکرد تعدیلی، میانجی، فرونشان، همرس است.
7- شاخصهای برازش میتوانند همزمان همه این رویکردها را تأیید کنند. آنها فقط برازش دادهها با مدلها را تأییدی میکنند و این به معنی تأیید فرضیهها در آن مدلها نیست.
خطوط راهنما برای رگرسیونهای چندگانه، تفکیکی و سلسله مراتبی
1- در رگرسیون چندگانه فرضیه نباید نوشته شود. همبستگیهای ساده فرضیه محسوب نمیشوند و جملاتی از قبیل اینکه همبستگیهای بین متغیرهای پیشبین، متغیر ملاک را پیشبینی میکند فرضیه نیست؛ زیرا معلوم نیست این ترکیب بین کدام متغیرهاست و بنابراین ابطالپذیر نیست. از این نوع رگرسیون فقط در مرحله اول یک پژوهش و برای یک جستوجوی اولیه میتوان استفاده کرد. گاهی ممکن است رگرسیون ساده یا همبستگی ساده در موارد نادر فرضیه پژوهشی باشد، مانند پژوهش عریضی و دژبان (2015) که در آن همبستگی بین دو موقعیت از یک سنجش که بهصورت گذشتهنگر مدنظر است. هدف آن پیوستگی بین این دو نوع موقعیت زمانی از یک سنجش است که در پژوهشهای گذشتهنگر وجود دارد.
2- عکس رگرسیون چندگانه، رگرسیون سلسله مراتبی دارای فرضیه و بر مبنای نظریههای استوار انجام میگیرد. ترتیب ورود متغیرها را برخلاف رگرسیون چندگانه پژوهشگر تعیین میکند. مجله باید در این زمینه پژوهشگران را هدایت کند تا مقالات عمیقتری بر مبنای رگرسیون سلسله مراتبی بنویسند. تابهحال هیچ مقاله با این سبک در مجله گزارش نشده است.
3- برخلاف رگرسیون چندگانه که ها یک متغیر y را پیشبینی میکند در رگرسیونهای چند متغیره چند متغیر وابسته پیشبینی میشود پژوهشگران با این شیوه تحلیل آماری آشنایی نداشته و در مجله رفاه اجتماعی گزارش نشده است. تحلیل همبستگی متعارف که نوعی از آن است نیز برای پژوهشگرانی که آشنایی فنی با علم آماری ندارند کمتر استفاده میشود. یک شیوه برای مجموعه هایی که ها را پیشبینی میکند تبدیل آن به J رگرسیون مجزاست که در هر یک ها یک y را پیشبینی میکند. این شیوه تحلیل به دلیل آن که روابط را همزمان مدنظر قرار نمیدهد دارای اشکال است. پژوهشگران گاهی به حدی با رگرسیون چندگانه ناآشنا هستند که آن را رگرسیون چند متغیره مینامند.
4- همبستگیهای تفکیکی میتوانند به پژوهشگر کمک کنند تا رابطه بین دو متغیر x و y را بهصورت خالص مشخص کند. بنابراین هرگاه این همبستگی بالاتر از 7/ 0 باشد به معنی آن است که متغیرها درواقع مربوط به فقط یک متغیر است.
5- همه مراحل مدل معادلات ساختاری باید بهدقت گزارش شود. بهبود مدل پیشنهادی اهمیت دارد اما مهمتر از آن مرحله مشخص کردن رابطه بین متغیرهاست که نیاز به یک پیشینه قوی دارد.
یادداشت (1): هنگامیکه دو متغیر دارای توزیع نرمال باشند، جمع آن دو متغیر بنا به یک قضیه در آمار همواره دارای توزیع نرمال است. در توزیع نرمال فاصله اطمینانی که برای فرضیه آزمایی طبق الگوی نیمن پیرسون ساخته میشود حول مقدار آماره در نمونه متقارن است و با افزودن و کاستن حاصلضرب خطای معیار اندازهگیری (SEM) در مقدار به دست میآید. در تحلیل میانجی با نمودار زیر
اثر غیرمستقیم (میانجی) حاصل ضریب (و نه حاصل جمع) دو ضریب مسیر و است. حتی اگر هر دو دارای توزیع نرمال باشند حاصل ضریب آنها معلوم نیست که نرمال باشد. به همین دلیل به جای روش معمول در توزیع نرمال (و آماره پارامتریک) که در ابتدای تحلیل میانجی t سوبل بود، از روشهای بازنمونهگیری مثل جک نایف و بوت استراپ استفاده میکنند.
ضمیمه
جدول (1): عناوین مقالههایی که به آنها انتقاد شده است
| شماره | نویسندگان | عنوان مجله | عنوان مقاله |
| 72 | غفاری، مؤمنی، یوسفی | رفاه اجتماعی | نقش انواع سرمایه در مشارکت اقتصادی زنان، مطالعه تطبیقی ... |
| 23 | روشنفکر و ذکائی | رفاه اجتماعی | جوانان، سرمایه اجتماعی و رفتارهای داوطلبانه |
| 80 | اصغریکما، برادران، زنجبر نوشری، جبهداری | رفاه اجتماعی | نقش واسطهای ادراک رفتارها فداکارانه همسر در رابطه بین شفقت به خود و خودمهارگری در درمانجویان وابسته به مواد |
| 71 | سعید ایرانی، منصور حقیقتیان و اصغر محمدی | رفاه اجتماعی | آسیبشناسی مسکن اجتماعی (مهر) با رویکرد نابرابری طبقاتی و انحرافات شهری تبریز |
| 60 | نامنی، عباسی، زارعی | رفاه اجتماعی | پیشبینی تعهد زناشویی بر اساس سبک عشقورزی و باورهای ارتباطی |
| 69 | نامنی و قربانی | رفاه اجتماعی | رابطه سلامت روان با کیفیت زندگی کودکان آزاردیده 7 تا 12 سال: اثر تعدیلکننده ادراک حمایت اجتماعی |
| 80 | گودرزی، محمدی، اصل ذاکر و رحمتی | رفاه اجتماعی | ارتباط سبکرفتار خانوادگی با رفتارهای پرخطر: با در نظر گرفتن نقش میانجی عاطفه منفی و دشواری در تنظیم هیجان |
| 48 | حقیقتیان و جعفری | رفاه اجتماعی | رابطه سرمایه اجتماعی درونگروهی با سلامت روان حاشیهنشینان |
| 72 | خسروانی، محسنی، صبور، خسروشاهی | رفاه اجتماعی | بررسی رابطه فقر شهری با فرهنگ فقر در محلههای فرودست شهر اراک |
| 78 | پاکنهاد، تقیپوریان، فرخ سرشت و سلیمیان | رفاه اجتماعی | تأثیر شبکههای اجتماعی مجازی بر سرمایه اجتماعی و قابلیتهای یادگیری سازمانی با نقش میانجی کنشهای یاریگرانه |
| 46 | مجتبی رفیعیان و حسین احمدزاده | رفاه اجتماعی | سنجش ظرفیتهای مشارکت اجتماعی در سیاستهای مداخله در محلات ناکارآمد شهری |
| 55 | رابطه دینداری با اعتماد اجتماعی | رفاه اجتماعی | فریده باقریانی |
| 55 | اجتماعی فردگرائی افراطی |
رفاه اجتماعی | پرینازل بیدل، علیاکبر محمدزاده، احمد صادقی |
| 56 | رابطه ویژگیهای خانواده و شخصیت کارآفرین | رفاه اجتماعی | بیژن زارع، مرضیه زارع |
| 34 | رابطه سکونت در شهر و اعتیاد | رفاه اجتماعی | صفر قائدرحمتی و مصطفی رضایی |
| 53 | تفاوتهای اجتماعی در سلامت اجتماعی، نقش فردگرائی ـ جمعگرایی | رفاه اجتماعی | منصوره نیکوگفتار |
| 52 | مشاغل در دوره بازنشستگی | رفاه اجتماعی | حمیدرضا عریضی، ریحانه دژبان |
| 33 | احمدفیروز آبادی و حسین ایمانی جاجرمی، | رفاه اجتماعی | سرمایه اجتماعی و توسعه اقتصادی ـ اجتماعی در کلانشهر تهران |
| 75 | مهشید موقر، حسین میرزاخانی، مجید ضرغام حاجبی | رفاه اجتماعی | پیشبینی افسردگی بر اساس حمایت اجتماعی |
| 55 | حسینعلی سرگزی و علیرضا محمدی آریا | رفاه اجتماعی | رابطه سرمایه اجتماعی با فرهنگسازمانی |
ملاحظات اخلاقی
نویسنده هشت ماه زمان برای مرور مقالات و همه منابع آن اختصاص داده است.
منابع مالی
این مرور انتقادی حامی مالی نداشته است.
تعارض منافع
این مرور با هیچ یک از آثار مؤلف همپوشی نداشته است.
متابعت از اخلاق پژوش
اصل انصاف در اخلاق سنگ زیربنای مقاله مرور انتقادی بوده است.
References
Amigó, S., Caselles, A. & Micó, J. C. (2008). A dynamic extraversion model. The brain's response to a single dose of a stimulant drug, British Journal of Mathematical and Statistical Psychology, 6(1), 211-231.
Asghari, H., Baradaran, M., Ranjbar Noushari, F., & Jobehdari, H. (2021). Mediating Role of Perceiving Wife's Selfless Behaviors in Relation to Self-compassion and Self-control in Drug Dependent Patients. Social Welfare Quarterly,21(80), 171-146.
Bidel P, Sadeghi A, Mahmoudzadeh A. (2015). The Relationship between Social Trust and Extreme Individualism (A Caes Stady of Mashhad). refahj. 14 (55) :167-198
Ghafari, G., Momeni, F., & Yousefi, N. (2019). The Effect of Capitals on Female Labour Force Participation: a Comparative Study on European::::: :union:::::: and Middle East Countries.Social Welfare Quarterly, 19(72), 9-54.
Goodarzi M, Mohammadi M, Aslezakerlighvan M, Rahmati F. (2021). Investigation of the Relationship between Family Relationship Styles and Risky Behaviors: The Mediating Role of Negative Affect and Emotion Regulation Difficulties. refahj. 21 (80) :147-169
Gross, A. G. (1989). The rhetorical invention of scientific invention: The emergence and transformation of a social norm, in Simons, H.W (ed) Rhetoric in the human sciences sage publications.
Haghighatian M, Jafari E. (2013).The Relationship of Bonding Social Capital with Mental Health among Slum dwellers. refahj. 13 (48) :131-149
Huillier, B. M. (2012). Making Meaning, Governing Change: Wittgenstein meets Humpty Dumpty. European Journal of Business and Social Science, 1(6), 124-139.
Keyvanan, M. Monadjemi, S.A., & Oryzi, H. (2016) Analysis of the Relevance between Human Brain Response to Stimulants and the Consumers Personality. Advances in Cognitive Science, 18(1), 1-13.
Kuhn, T. S. (2000). The road since structure: philosophical essays, 1970-1993, with an autobiographical interview. University of Chicago Press.
Lee, H. N. (2019). Self-Compassion and Depression Across Culture: Comparisons of Emerging Adults in China and the United States.
López, A., Sanderman, R., Smink, A., Zhang, Y., Van Sonderen, E., Ranchor, A., & Schroevers, M. J. (2015). A reconsideration of the Self-Compassion Scale’s total score: self-compassion versus self-criticism. PloS one, 10(7), e0132940.
Lyotard, J. F. (1984). The postmodern condition: A report on knowledge, translation from the French by Bennington, G & Massumi, B. University of Minnesota press, Minneapolis.
Namani, E., & Ghorbani, S. A. (2018). The relationship between mental health and the quality of life among abused children 7 to 12 years old: moderating effect of perceived social support. Social Welfare Quarterly, 18(69), 77-55.
Nameni, E., Abasi, F., & Zarei, A. Z. (2016). Predicting marital commitment on the basis of love style and relationship beliefs. Social Welfare Quarterly, 16(60), 87-107.
Paknahad F, Taghipourian M, Farokhseresht B, Salimian M. (2020). Investigating the Impact of Virtual Social Networks on Social Capital and Organizational Learning Capabilities with the Mediating Role of Helpful Activities. refahj. 20 (78) :47-76
Rafieian M, Ahmadzadeh Nanva H. (2012). Evaluating the Capacities of Social Participation in Interference Policy in Inefficient Region. refahj. 12 (46) :407-429
Roshanfekr, P., & Zokaei, S. (2007). Youth, social capital and volunteering. Social Welfare Quarterly, 6(23), 113-146.
Seng, J. S., Faan, C. Lopez, W. D. Sperlich, M and Meldrum, C. D. R. (2012). Marginalized identities, discrimination burden and mental health, Empirical exploration of an interpersonal- level approach to modeling intersectionality, soc. ci Med, 75, 2437- 2445.
Tarka, P. (2018). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences. Quality & quantity, 52(1), 313-354.
Zisman, C., & Ganzach, Y. (2021). In a representative sample grit has a negligible effect on educational and economic success compared to intelligence. Social Psychological and Personality Science, 12(3), 296-303.
Mahmoud Alilou. M., Hashemi, T., Bairami, M. Bakhshipour, A. Sharifi, M. A. (2014). Investigation the Relationship between Childhood Maltreatment, Early losses and Separations and Emotion Dysregulation with Borderline Personality Disorder.
Amigó, S., Caselles, A. & Micó, J. C. (2008). A dynamic extraversion model. The brain's response to a single dose of a stimulant drug, British Journal of Mathematical and Statistical Psychology, 6(1), 211-231.
Asghari, H., Baradaran, M., Ranjbar Noushari, F., & Jobehdari, H. (2021). Mediating Role of Perceiving Wife's Selfless Behaviors in Relation to Self-compassion and Self-control in Drug Dependent Patients. Social Welfare Quarterly,21(80), 171-146.
Bidel P, Sadeghi A, Mahmoudzadeh A. (2015). The Relationship between Social Trust and Extreme Individualism (A Caes Stady of Mashhad). refahj. 14 (55) :167-198
Ghafari, G., Momeni, F., & Yousefi, N. (2019). The Effect of Capitals on Female Labour Force Participation: a Comparative Study on European::::: :union:::::: and Middle East Countries.Social Welfare Quarterly, 19(72), 9-54.
Goodarzi M, Mohammadi M, Aslezakerlighvan M, Rahmati F. (2021). Investigation of the Relationship between Family Relationship Styles and Risky Behaviors: The Mediating Role of Negative Affect and Emotion Regulation Difficulties. refahj. 21 (80) :147-169
Gross, A. G. (1989). The rhetorical invention of scientific invention: The emergence and transformation of a social norm, in Simons, H.W (ed) Rhetoric in the human sciences sage publications.
Haghighatian M, Jafari E. (2013).The Relationship of Bonding Social Capital with Mental Health among Slum dwellers. refahj. 13 (48) :131-149
Huillier, B. M. (2012). Making Meaning, Governing Change: Wittgenstein meets Humpty Dumpty. European Journal of Business and Social Science, 1(6), 124-139.
Keyvanan, M. Monadjemi, S.A., & Oryzi, H. (2016) Analysis of the Relevance between Human Brain Response to Stimulants and the Consumers Personality. Advances in Cognitive Science, 18(1), 1-13.
Kuhn, T. S. (2000). The road since structure: philosophical essays, 1970-1993, with an autobiographical interview. University of Chicago Press.
Lee, H. N. (2019). Self-Compassion and Depression Across Culture: Comparisons of Emerging Adults in China and the United States.
López, A., Sanderman, R., Smink, A., Zhang, Y., Van Sonderen, E., Ranchor, A., & Schroevers, M. J. (2015). A reconsideration of the Self-Compassion Scale’s total score: self-compassion versus self-criticism. PloS one, 10(7), e0132940.
Lyotard, J. F. (1984). The postmodern condition: A report on knowledge, translation from the French by Bennington, G & Massumi, B. University of Minnesota press, Minneapolis.
Namani, E., & Ghorbani, S. A. (2018). The relationship between mental health and the quality of life among abused children 7 to 12 years old: moderating effect of perceived social support. Social Welfare Quarterly, 18(69), 77-55.
Nameni, E., Abasi, F., & Zarei, A. Z. (2016). Predicting marital commitment on the basis of love style and relationship beliefs. Social Welfare Quarterly, 16(60), 87-107.
Paknahad F, Taghipourian M, Farokhseresht B, Salimian M. (2020). Investigating the Impact of Virtual Social Networks on Social Capital and Organizational Learning Capabilities with the Mediating Role of Helpful Activities. refahj. 20 (78) :47-76
Rafieian M, Ahmadzadeh Nanva H. (2012). Evaluating the Capacities of Social Participation in Interference Policy in Inefficient Region. refahj. 12 (46) :407-429
Roshanfekr, P., & Zokaei, S. (2007). Youth, social capital and volunteering. Social Welfare Quarterly, 6(23), 113-146.
Seng, J. S., Faan, C. Lopez, W. D. Sperlich, M and Meldrum, C. D. R. (2012). Marginalized identities, discrimination burden and mental health, Empirical exploration of an interpersonal- level approach to modeling intersectionality, soc. ci Med, 75, 2437- 2445.
Tarka, P. (2018). An overview of structural equation modeling: its beginnings, historical development, usefulness and controversies in the social sciences. Quality & quantity, 52(1), 313-354.
Zisman, C., & Ganzach, Y. (2021). In a representative sample grit has a negligible effect on educational and economic success compared to intelligence. Social Psychological and Personality Science, 12(3), 296-303.
Mahmoud Alilou. M., Hashemi, T., Bairami, M. Bakhshipour, A. Sharifi, M. A. (2014). Investigation the Relationship between Childhood Maltreatment, Early losses and Separations and Emotion Dysregulation with Borderline Personality Disorder.
نوع مطالعه: مروری 1 |
موضوع مقاله:
رفاه اجتماعی
دریافت: 1400/8/16 | پذیرش: 1402/2/19 | انتشار: 1402/2/19
دریافت: 1400/8/16 | پذیرش: 1402/2/19 | انتشار: 1402/2/19
ارسال پیام به نویسنده مسئول
| بازنشر اطلاعات | |
 |
این مقاله تحت شرایط Creative Commons Attribution-NonCommercial 4.0 International License قابل بازنشر است. |

تماس با ما
فصلنامه رفاه اجتماعی
تهران، اوین، بلوار دانشجو، خ کودکیار، دانشگاه علوم توانبخشی و سلامت اجتماعی، ساختمان فارابی
تلفن دفتر نشریه: 02171732851
وب سایت: http://refahj.uswr.ac.ir
ایمیل: refahj@uswr.ac.ir
